机器学习中的偏差与方差2025年06月13日 | 阅读 6 分钟 机器学习是人工智能的一个分支,它允许机器进行数据分析和预测。然而,如果机器学习模型不准确,它可能会产生预测错误,这些预测错误通常被称为偏差和方差。在机器学习中,这些错误总是存在的,因为模型预测和实际预测之间总会存在微小的差异。机器学习/数据科学分析师的主要目标是减少这些错误,以获得更准确的结果。在本主题中,我们将讨论偏差和方差、偏差-方差权衡、欠拟合和过拟合。但在开始之前,让我们先了解一下机器学习中的错误是什么?  机器学习中的错误?在机器学习中,错误是衡量算法对先前未知数据集进行预测的准确性的度量。根据这些错误,可以选择性能最佳的机器学习模型。机器学习中主要有两种类型的错误,它们是
无论使用哪种算法。这些错误的根源是未知变量,其值无法减小。 什么是偏差 (Bias)?一般来说,机器学习模型会分析数据,从中找出模式并进行预测。在训练过程中,模型会学习数据集中的这些模式,并将它们应用于测试数据进行预测。在进行预测时,模型所做的预测值与实际值/预期值之间会产生差异,这种差异被称为偏差误差或因偏差引起的错误。它可以被定义为机器学习算法(如线性回归)无法捕获数据点之间真实关系的能力。每种算法都存在一定程度的偏差,因为偏差源于模型中的假设,这使得目标函数易于学习。模型具有以下两种情况:
通常,线性算法具有高偏差,因为它们能快速学习。算法越简单,引入的偏差就越高。而非线性算法通常具有低偏差。 一些具有低偏差的机器学习算法示例包括决策树、K近邻和支持向量机。同时,具有高偏差的算法有线性回归、线性判别分析和逻辑回归。 降低高偏差的方法高偏差主要由于模型过于简单而产生。以下是一些降低高偏差的方法:
什么是方差误差 (Variance Error)?方差表示当使用不同的训练数据时,预测值变化的量。简单来说,方差表示一个随机变量与其期望值之间的差异程度。理想情况下,模型从一个训练数据集到另一个训练数据集的变化不应太大,这意味着算法应能很好地理解输入和输出变量之间的隐藏映射。方差误差分为低方差或高方差。 低方差 (Low variance) 表示目标函数的预测值在训练数据集变化时变化很小。同时,高方差 (High variance) 表示目标函数的预测值在训练数据集变化时变化很大。 高方差模型会从训练数据集中学习很多,并在训练数据上表现良好,但它无法很好地泛化到未见过的数据集。因此,这类模型在训练数据集上给出良好结果,但在测试数据集上却显示出很高的错误率。 由于高方差模型会从数据集中学习过多,这会导致模型过拟合。高方差模型存在以下问题:
通常,非线性算法具有很高的灵活性来拟合模型,因此具有高方差。 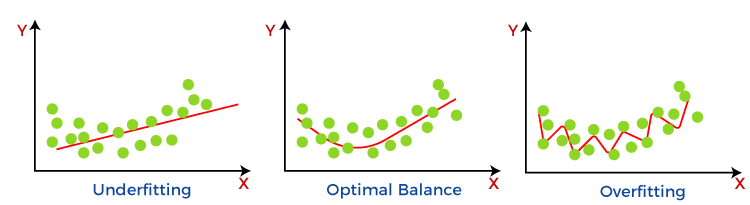 一些具有低方差的机器学习算法示例是线性回归、逻辑回归和线性判别分析。同时,具有高方差的算法有决策树、支持向量机和K近邻。 降低高方差的方法
偏差-方差的不同组合偏差和方差有四种可能的组合,如下方图所示: 
如何识别高方差或高偏差?如果模型具有以下特征,则可以识别出高方差: 
如果模型具有以下特征,则可以识别出高偏差:
偏差-方差权衡 (Bias-Variance Trade-Off)在构建机器学习模型时,务必注意偏差和方差,以避免模型出现过拟合和欠拟合。如果模型非常简单,参数很少,它可能具有低方差和高偏差。反之,如果模型具有大量的参数,它将具有高方差和低偏差。因此,需要平衡偏差和方差误差,这种偏差误差和方差误差之间的平衡被称为偏差-方差权衡。  为了模型的准确预测,算法需要低方差和低偏差。但这并非不可能,因为偏差和方差是相互关联的。
偏差-方差权衡是监督学习中的一个核心问题。理想情况下,我们需要一个模型,它能够准确地捕捉训练数据的规律,同时又能很好地泛化到未见过的数据集。然而,同时做到这两点是不可能的。因为高方差的算法可能在训练数据上表现良好,但可能导致对噪声数据的过拟合。而高偏差算法生成的模型过于简单,甚至可能无法捕捉数据中的重要规律。因此,我们需要找到偏差和方差之间的最佳点,以构建一个最优模型。 因此,偏差-方差权衡就是找到一个最佳点来平衡偏差和方差误差。 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India

