机器学习中的信用卡审批2025年3月17日 | 阅读13分钟  信用评分卡在金融行业被广泛用作风险控制措施。这些评分卡利用信用卡申请人提供的个人信息和数据来评估未来潜在违约和信用卡债务的可能性。基于此评估,银行可以就是否批准信用卡申请做出明智的决定。信用评分提供了一种客观的方式来衡量和量化所涉及的风险水平。 信用卡审批是银行业的一个关键流程。传统上,银行依赖人工评估信用度,这既耗时又容易出错。然而,随着机器学习(ML)算法的出现,信用卡审批流程得到了显著简化。 机器学习算法能够分析大量数据并提取模式,这使其在信用卡审批中具有无价的价值。通过使用包含申请人信息、其财务行为和信用历史的过往数据训练机器学习模型,银行可以更准确、更高效地预测信用度。 使用机器学习进行信用卡审批的优势
使用机器学习进行信用卡审批的挑战
为了更好地理解,我们将尝试在代码中实现它,这里将尝试找出申请人是“好”客户还是“坏”客户。 数据定义有两个 .csv 文件,例如 1. application_record.csv
2. credit_record.csv
代码 导入库读取数据集特征工程在此,我们将旨在从可用数据中提取最相关的信息,并以机器学习算法可以有效学习的方式表示它。 这里,我们将根据“ID”列,合并来自两个 DataFrame(data 和 begin_month)的信息。它向数据 DataFrame 添加了一个新列“begin_month”,表示来自 record DataFrame 的每个唯一“ID”的“MONTHS_BALANCE”的最小值。 目标变量通常,目标风险用户预计占所有用户的约 3%。在这种情况下,我们已将逾期付款超过 60 天的用户识别为目标风险用户。这些特定样本标记为“1”,而其余样本标记为“0”。 现在我们将创建目标变量。  “否”出现 45,318 次,约占总值的 98.55%。 “是”出现 667 次,约占总值的 1.45%。 特点现在我们将对特征进行探索性数据分析,在此我们将检查、分析并对特征进行各种操作。 ivtable DataFrame 将包含原始 DataFrame 中除 namelist 中指定的列之外的其余列。 定义 calc_iv 函数来计算信息值和 WOE 值 它将 DataFrame 中的分类特征转换为哑变量。 它根据 DataFrame 中的数值列创建分类箱。 二元特征二元特征,也称为二元变量或二元指标,是只能取两个不同值(通常表示为 0 和 1)的分类变量。这些特征用于指示数据集中是否存在特定特征或属性。 我们将寻找各种二元特征及其各种属性。 性别 (Gender) 输出  有车或无车 输出  有房产或无房产 输出  有电话或无电话 输出  有电子邮件或无电子邮件 输出  有工作电话或无工作电话 输出  连续变量连续变量,也称为定量或数值变量,是可以在特定范围内取任何值的测量值。与只有两个可能值的二元特征不同,连续变量可以在给定区间内具有无限数量的可能值。现在我们将寻找各种连续变量及其属性。 子女人数 输出  输出  年收入 输出   输出  输出   输出  工作年限 输出  输出  家庭规模 输出  输出  分类特征分类特征,也称为定性或名义变量,表示属于不同类别或组的特征或属性。与具有一系列数值的连续变量不同,分类特征具有有限数量的离散值或标签。现在我们将查看各种分类特征及其属性。 收入类型 输出  输出  房屋类型 输出  教育 输出  输出  输出  IV 和 WOE证据权重 (WoE) woe_i = ln((P(yi) / P(ni)) = ln((yi / ys) / (ni / ns)) 其中
信息值 (IV) IV = Σ[(Pyi - Pni) * ln(Pyi / Pni)] 其中
IV 值衡量变量的预测能力。 IV 值与预测能力之间的关系
输出  年龄组(agegp)的 IV 值最高,为 0.0659351,表明具有相对较强的预测能力,而其他变量,如工作电话(wkphone)、子女人数(ChldNo)、电话(phone)、收入类型(inctp)、电子邮件(email)、汽车所有权(Car)和职业类型(occyp)的 IV 值非常低,表明它们几乎没有预测能力。 输出  分割数据集现在我们将把数据集分成训练集和测试集。 建模然后,我们将继续训练和评估不同的机器学习算法,包括逻辑回归、决策树、随机森林、支持向量机 (SVM) 和梯度提升方法。每种算法都有其自身的优点和特点,因此比较它们的性能并选择最适合我们信用卡审批预测任务的算法非常重要。 1. 逻辑回归输出  逻辑回归(LR)的准确度得分为 0.61215。这表明模型正确预测信用卡审批的能力是中等的。 2. 决策树输出  决策树分类器(DTC)表现更好,准确度得分为 0.82897。这表明该模型在捕获数据中的模式和关系以进行信用卡审批预测方面更有效。 3. 随机森林输出 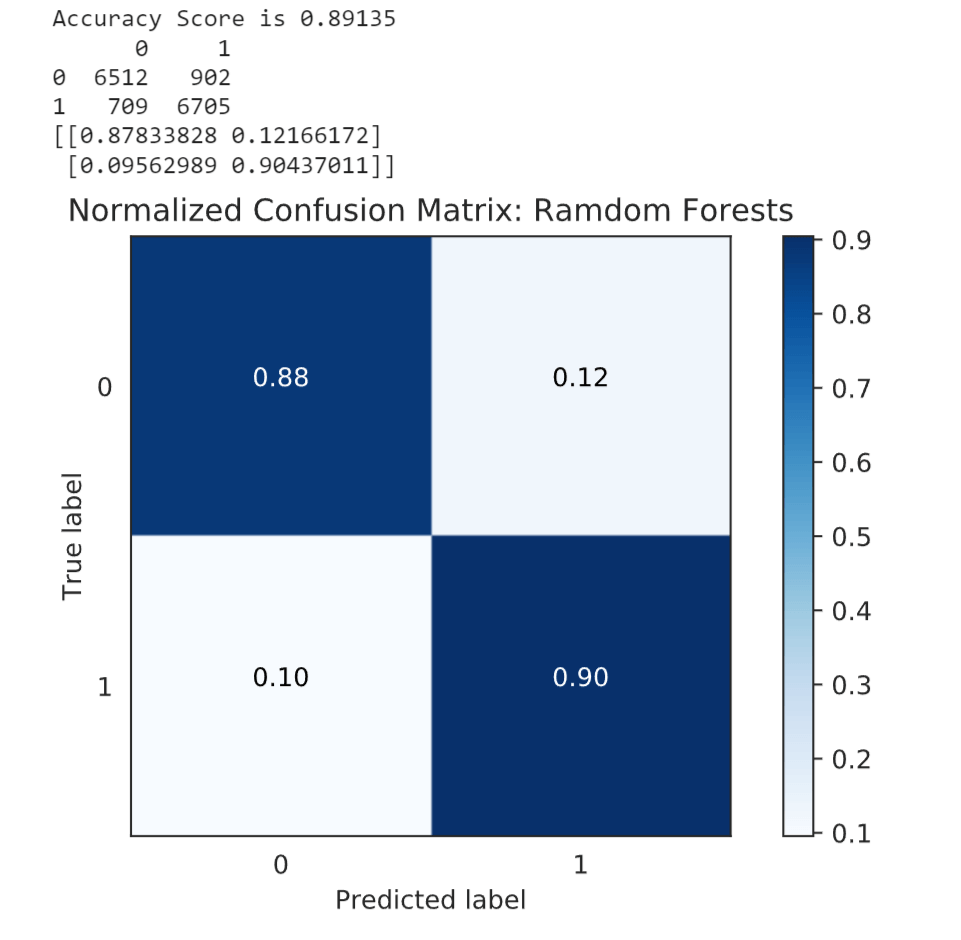 随机森林分类器(RFC)的准确度得分更高,为 0.89459。这表明随机森林模型中决策树的集成改进了预测性能,优于单个决策树。 4. SVM输出  支持向量机(SVM)的准确度得分较低,为 0.59367,这表明它们在这种情况下可能无法有效捕获信用卡审批预测任务的复杂性。 5. LightGBM输出  Light GBM 获得了 0.90356 的高准确度得分,这表明该模型中使用的梯度提升算法有效地提高了预测准确度,优于其他模型。 输出  输出  6. XGBoost输出  XGBoost 的准确度得分高达 0.93789。这表明 XGBoost 中采用的极限梯度提升算法捕获了数据中复杂的模式,并对信用卡审批做出了高度准确的预测。 输出  7. CatBoost输出  然而,CatBoost 的准确度得分相对较低,为 0.50081。这表明该模型在此上下文中表现不佳,可能需要进一步调查或参数调整以提高其预测能力。 XGBoost 模型在所考虑的模型中表现出最高的准确度,其次是 Light GBM 和随机森林分类器。这些模型似乎更适合预测信用卡审批。 结论使用机器学习进行信用卡审批具有众多优势,包括提高准确性、加快处理速度、提供个性化服务和降低风险。通过利用机器学习算法,金融机构可以简化审批流程、提供定制的信用卡解决方案并做出明智的贷款决策。然而,至关重要的是解决与数据隐私、模型可解释性和公平性相关的挑战,以确保机器学习在信用卡审批中负责任和道德地实施。通过适当的考虑和监督,机器学习有潜力彻底改变贷款格局,造福消费者和贷方。 下一个主题使用机器学习预测肝病 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
