机器学习中的作物产量预测2025年6月24日 | 阅读10分钟  作物产量预测是农业的重要方面,有助于农民就其作物做出明智的决策。 它涉及根据诸如土壤类型、天气条件和作物管理实践等各种因素来估算给定区域将生产的作物数量。近年来,机器学习(ML)已成为预测作物产量的强大工具。 机器学习是人工智能(AI)的一个分支,它允许计算机从数据中学习,而无需显式编程。这使其成为作物产量预测的理想选择,因为它可以识别大量数据中的模式和关系,并基于这些关系进行预测。 有各种类型的机器学习算法可用于作物产量预测,包括回归、决策树和人工神经网络。 回归算法常用于预测作物产量,因为它们易于理解且易于实现。这些算法使用一组输入(例如天气数据、土壤数据和管理实践)来预测输出(作物产量)。 决策树算法也用于作物产量预测。它们使用树状结构来模拟决策及其潜在后果。算法首先基于最重要的输入因素做出决策,然后根据后续输入继续做出其他决策。算法的最终结果是作物产量的预测。 人工神经网络是更复杂的机器学习算法,其模型模仿人脑的结构和功能。它们特别适合作物产量预测,因为它们可以处理大量数据并识别复杂的模式和关系。 要为作物产量预测实现机器学习,需要大量的作物产量数据。这些数据应包括有关作物的信息,例如作物类型、地点和种植日期。此外,还应收集天气条件和土壤特征的数据。然后,在这些数据上训练机器学习算法,以学习输入和输出之间的关系。 一旦机器学习算法训练完毕,就可以将其用于预测新区域的作物产量。这是通过输入必要的数据(例如天气条件和土壤特征)并允许算法进行预测来完成的。 在本文中,我们将使用机器学习技术来预测全球消费的十大产量。 这些作物包括:
 现在我们将它实现到代码中。 1. 导入库2. 数据收集和清洗数据收集和清洗是机器学习中的一个基本步骤,因为它可以显著影响模型的准确性和性能。 作物产量数据从粮农组织网站获取了全球产量最高的十种作物。收集到的信息包括国家、项目、年份(1961年至2016年)和产量值。 输出  产量数据集中总共有56717行,12列。 输出  输出  输出 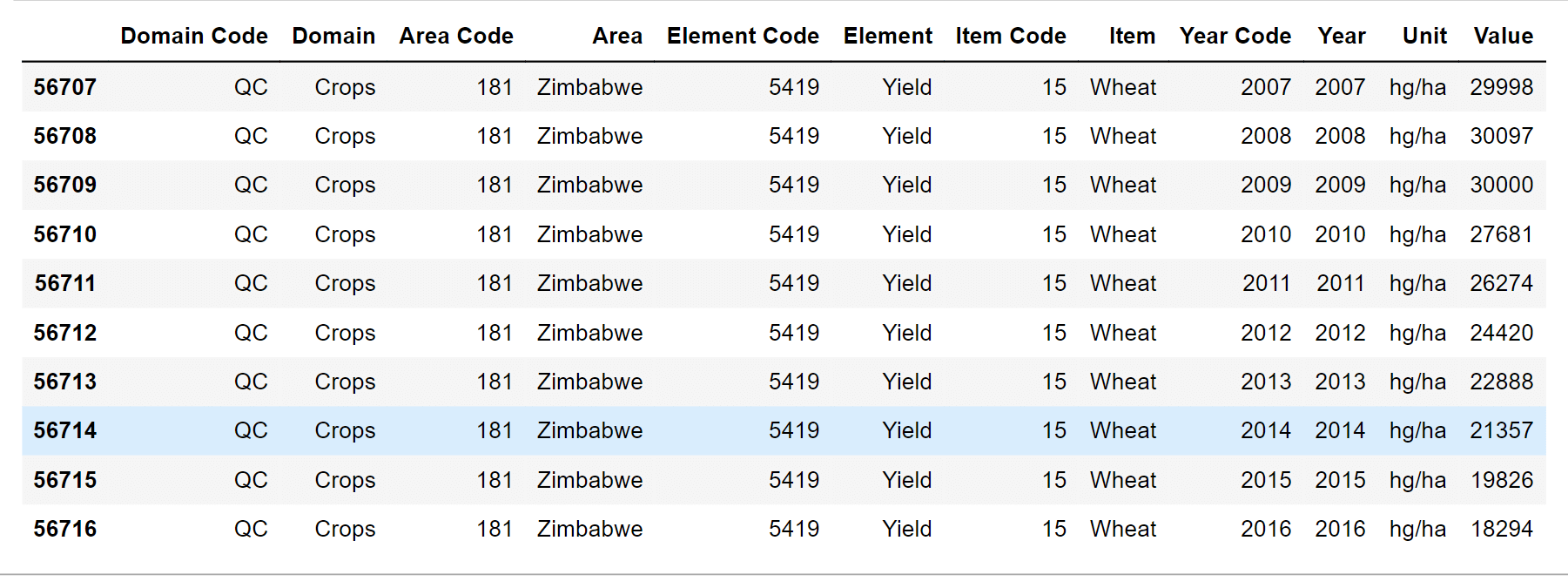 仔细查看CSV文件中的列,我们可以将“Value”重命名为“hg/ha yield”,以使其更清楚地表明这是我们作物产量的生产价值。此外,还应删除区域代码、域、项目代码等无关列。 输出 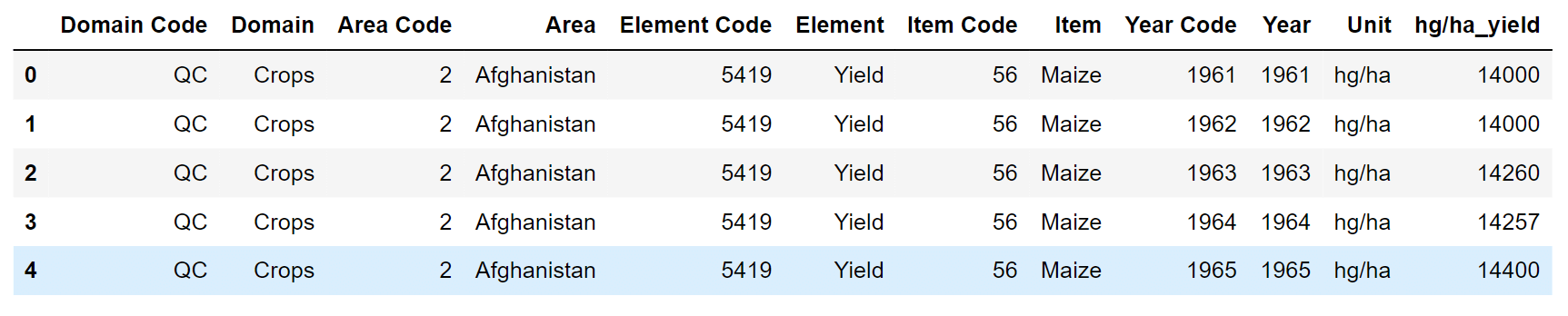 输出  输出  输出  气候数据:降雨量降水量和温度是气候元素。影响植物生长和发育的环境变量由非生物因素组成,例如土壤和杀虫剂。 降雨量对农业的影响很大。该项目的年降雨量信息来自世界数据银行。 输出  输出  现在,我们将检查数据集中的数据类型。 输出  我们需要将 `average_rain_fall_mm_per_year` 的数据类型从 object 更改为 float。另外,请记住它还包含一些缺失值。 输出  之后,我们将删除数据集中的任何空白行,并根据年份和区域列合并产量数据框和降雨数据框。 输出  降雨数据框的年份范围为1985年至2016年。 现在,我们将根据年份和区域列合并产量数据框和降雨数据框。 输出  由于降雨数据从1985年开始,我们可以看到年份现在从1961年开始的第一个产量数据框开始。 输出  杀虫剂数据使用粮农组织数据库,还收集了每个国家和项目使用的杀虫剂。 输出  现在,我们将列名“Value”重命名为“pesticides_tones”。 同时,我们还将删除不需要的列,这些列对于未来用途不重要。 输出  输出  输出  现在,我们将杀虫剂数据框与主数据框合并。 输出  输出  平均温度使用世界银行数据确定了每个国家的平均温度。 输出  输出  根据我们的观察,平均温度范围从1743年到2013年,有几行是空的,我们需要将其删除。 接下来,我们将重命名列。 输出  输出  输出  随着我们将其他数据框合并进来,主数据框的形状正在改变。 输出  查找主数据框中的空值。 输出  不幸的是,`average_rain_fall_mm_per_year` 列中有六个空值。 输出  我们需要删除上述行。 输出: 太好了,没有空值了! 3. 数据探索经过所有合并,我们得到了 `dataframe_main` 作为最终获得的数据框。现在我们需要对其进行探索。 输出  输出  每一列的值都有显著的波动,我们稍后会将其缩减。 输出  数据框中的101个国家按最高产量输出(前10名)排名,所以 输出  在数据集中,印度拥有最高的产量。 分组的项目包括: 输出  印度木薯和土豆产量最高。土豆在四个国家中占有最高的百分比,似乎是样本中最普遍的作物。 最终数据框包含101个国家的数据,涵盖23年(1990年至2013年)。 现在,当我们查看数据框列之间的链接时,将相关矩阵显示为热图是一种快速验证列之间相关性的便捷方法。 输出  上述相关图显示,数据框的任何列之间都没有关联。 4. 数据预处理数据预处理是一种将不干净的数据转换为干净数据集的方法。换句话说,当数据从各种来源获取时,它会以一种原始的方式获取,使得分析变得不可能。 输出  5. 对分类变量进行编码数据框中有两列类别,它们是具有标签值而不是数值的变量。可用值的范围通常限于预设的集合,例如在此示例中,项目和国家的值。 许多机器学习算法无法直接处理标签数据。它们要求所有输入和输出变量都是数字。 因此,必须将分类数据转换为数值数据。独热编码方法涉及将分类信息转换为可提供给 ML 算法的格式,以帮助它们提高预测性能。为了达到此目的,将使用独热编码方法将这两列转换为独热数值数组。 数据集中元素的数值由类别值表示。对于每个类别,将使用此编码创建一个二进制列,并将结果作为矩阵返回。 输出  输出  输出  6. 特征缩放上面显示的数据集中的特征具有广泛的量级、单位和范围。特征的量级在距离计算中的重要性将远远大于特征的量级。 我们必须使所有特征的量级相等,以减少这种影响。缩放可以帮助实现这一点。 缩放所有特征值并删除年份列后,结果数组将如下所示: 输出  7. 训练集和测试集训练数据集和测试数据集将从原始数据集中创建。数据中的不平衡通常是模型在训练期间需要尽可能多的数据点所致。对于训练/测试,典型百分比为 70/30 或 80/20。 用于教机器学习算法学习并做出准确预测的第一个数据集称为训练数据集。数据集的70%是训练数据集。 但是,测试数据集用于评估使用训练数据集的 ML 算法的教学效果。由于 ML 算法已经“知道”预期的输出,因此通过简单地重用训练数据集来测试方法是没有意义的。测试数据集占数据集的30%。 8. 模型比较和选择输出  R2(决定系数)回归评分函数将是评估措施的基础,它将指示回归模型中项目(作物)的方差百分比。R2 分数显示了单词(数据点)拟合曲线或直线有多接近。 R2 是一个统计指数,范围从 0 到 1,衡量回归线与拟合它的数据的接近程度。如果为 1,则模型准确预测了数据的 100% 方差;如果为 0,则模型准确预测了 0% 的方差。 根据上述结果,梯度提升回归器以96%的R2分数位居第二,其次是决策树回归器。 我们还将进行数学计算。但是,调整后的 R2 考虑了模型中的项数,并且仍然显示了项与曲线或直线的拟合程度。当模型中包含更多无用的变量时,调整后的 R2 会下降。更多有意义的变量会产生更高的调整后 R2。调整后的 R2 永远不会大于 R2 或与 R2 相同。 输出  输出  输出  输出  输出  模型结果与结论输出  仅获取模型重要性列表中的前 7 个特征。 输出  输出  由于土豆是数据集中产量最高的作物,因此在模型的决策过程中占有最大的权重。就红薯而言,我们观察到数据集中的一些作物具有最高的特征值,以及木薯,其中杀虫剂的影响是第三重要的特征。 鉴于印度拥有数据集中的大多数作物,如果该作物在那里种植,那是有道理的。降雨量和温度紧随其后。这些变量对模型预测的作物产量期望产生了重大影响,证明了它们最初的假设是正确的。 总之,使用机器学习进行作物产量预测有潜力彻底改变农业。通过提供更准确的预测,改进决策,提高效率和增强可持续性,这项技术可以帮助农民获得更好的产量和更具盈利能力的企业。尽管使用机器学习进行作物产量预测存在一些挑战,但其好处显而易见,我们可以预见这项技术在未来几年将不断取得进展。 下一个主题为什么训练损失远远大于验证损失 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India

