K-Medoids 聚类 - 理论解释2025年6月23日 | 阅读 6 分钟 K-Medoids 和 K-Means 是分区聚类(Partition Clustering)中的两种聚类机制。首先,聚类是将一组数据点/对象划分为相似对象类的过程,使得一个簇中的所有对象都具有相似的特征。,一组 n 个对象根据它们的相似性被划分为 k 个簇。 两位统计学家 Leonard Kaufman 和 Peter J. Rousseeuw 提出了这种方法。本教程将解释 K-Medoids 的作用、其应用以及 K-Means 和 K-Medoids 之间的区别。 K-medoids 是一种无监督方法,用于对未标记数据进行聚类。它是 K-Means 算法的一种改进版本,主要设计用于处理对离群点数据敏感的问题。与其它分区算法相比,该算法简单、快速、易于实现。 划分将按照以下方式进行:
这里简要回顾一下 K-Means 聚类:在 K-Means 算法中,给定 k 值和无标记数据:
K-Means 算法的问题在于算法需要处理离群点数据。离群点是一个与其他点不同的点。所有离群点数据都会出现在一个不同的簇中,并吸引其他簇与之合并。离群数据会将簇的均值提高多达 10 个单位。因此,K-Means 聚类高度受离群数据的影响。 K-Medoids中心点(Medoid):中心点是簇中到其他数据点的距离之和最小的点。 (或) 中心点是簇中与其他簇内点相似度(dissimilarities)最小的点。 K-Medoids 算法使用中心点(Medoid)作为参考点,而不是 K-Means 算法中的中心点(Centroid)。 K-Medoids 聚类有三种算法:
PAM 是这三种算法中最强大的,但缺点是时间复杂度高。以下 K-Medoids 使用 PAM 进行。后续部分将介绍 CLARA 和 CLARANS。 算法给定 k 值和无标记数据
这里有一个例子来阐明理论: 数据集
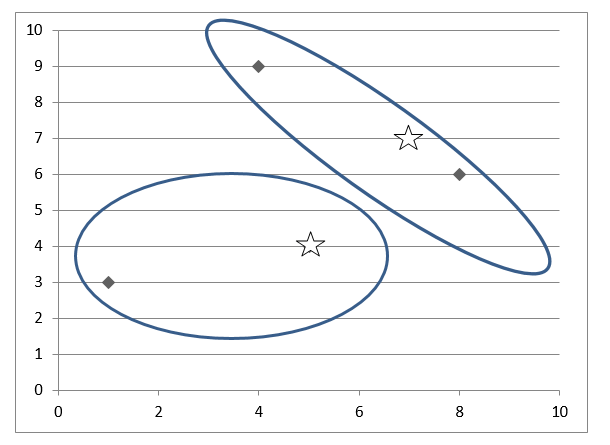
散点图 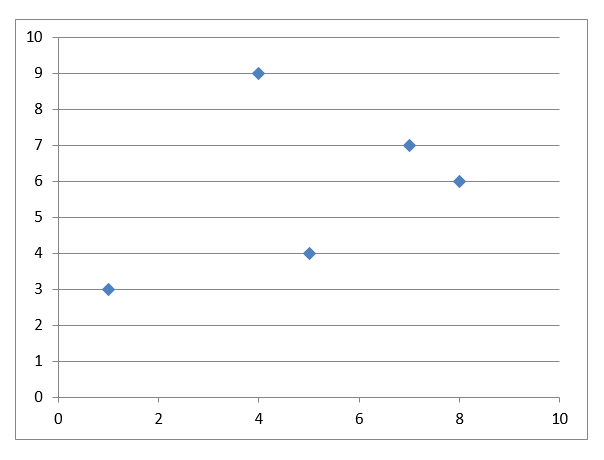 如果 k 指定为 2,我们需要将数据点划分为 2 个簇。
曼哈顿距离:|x1 - x2| + |y1 - y2|
簇 1 0 簇 2 1, 3
M1(5, 4) 和 M2(4, 9)
簇 1 2, 3 簇 2 1
M1(5, 4) 和 M2(7, 7)
簇 1 2 簇 2 3, 4
M1(7, 7) 和 M2(8, 6)
簇 1 4 簇 2 0, 2
 PAM 的局限性时间复杂度:O(k * (n - k)2)每个节点的可能组合:k*(n - k) 每次计算的成本:(n - k) 总成本:k*(n - k)2 因此,PAM 适合并推荐用于小型数据集。 CLARA它是 PAM 的扩展,用于支持大型数据集的中心点聚类。该算法从数据集中选择数据样本,对每个样本应用 Pam,并输出这些样本中最佳的聚类。这比 PAM 更有效。我们应该确保选择的样本没有偏见,因为它们会影响整个数据的聚类。 CLARANS该算法选择一个邻居样本进行检查,而不是从数据集中选择样本。在每一步,它都会检查每个节点的邻居。该算法的时间复杂度为 O(n2),它是所有中心点算法中最好、效率最高的。 使用 K-Medoids 的优点
缺点
K-Means 与 K-Medoids
有意义的离群簇例如,对人们收入的数据集进行聚类,以分析和理解每个簇中个人的购买和投资行为。 在这里,离群数据是高收入人群——亿万富翁。所有这样的人都倾向于购买和投资更多。因此,在这种情况下,为亿万富翁创建一个单独的簇是有意义的。 在 K-Medoids 中,它会将这些数据合并到上层阶级簇中,从而丢失了聚类中有意义的离群数据,这是 K-Medoids 在特殊情况下的一个缺点。 下一主题机器学习在营销中的应用 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
