机器学习中的过拟合与欠拟合2025 年 6 月 4 日 | 阅读 4 分钟 过拟合和欠拟合是机器学习中出现的两个主要问题,它们会降低机器学习模型的性能。 每个机器学习模型的主要目标是泛化能力强。这里的泛化是指机器学习模型通过适应给定的未知输入集来提供合适输出的能力。这意味着在数据集上进行训练后,它可以产生可靠和准确的输出。因此,欠拟合和过拟合是需要检查模型性能以及模型是否泛化良好的两个术语。 在理解过拟合和欠拟合之前,让我们先了解一些有助于更好地理解这个主题的基本术语:
过拟合当我们的机器学习模型试图覆盖给定数据集中存在的所有数据点或超过所需数据点时,就会发生过拟合。因此,模型开始缓存数据集中存在的噪声和不准确的值,所有这些因素都会降低模型的效率和准确性。过拟合模型具有低偏差和高方差。 为模型提供的训练越多,发生过拟合的可能性就越大。这意味着我们训练模型越多,发生过拟合模型的可能性就越大。 过拟合是监督学习中发生的主要问题。 示例: 下面的线性回归输出图可以帮助理解过拟合的概念。  从上图可以看出,模型试图覆盖散点图中存在的所有数据点。它看起来可能很有效,但实际上并非如此。因为回归模型的目的是找到最佳拟合线,但在这里我们没有找到任何最佳拟合,因此它将产生预测误差。 如何避免模型过拟合过拟合和欠拟合都会导致机器学习模型性能下降。但主要原因是过拟合,因此有一些方法可以减少模型中过拟合的发生。
欠拟合当我们的机器学习模型无法捕捉数据的底层趋势时,就会发生欠拟合。为了避免模型过拟合,可以在早期阶段停止输入训练数据,因此模型可能无法从训练数据中学习到足够的信息。因此,它可能无法找到占主导地位的趋势的最佳拟合。 在欠拟合的情况下,模型无法从训练数据中学习到足够的信息,因此会降低准确性并产生不可靠的预测。 欠拟合模型具有高偏差和低方差。 示例: 我们可以使用下面的线性回归模型输出来理解欠拟合。 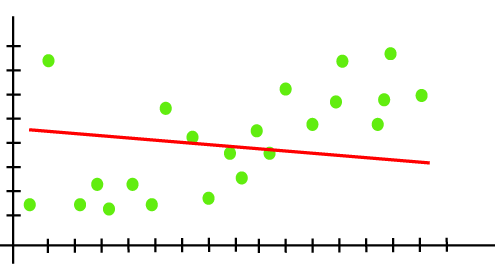 从上图可以看出,模型无法捕捉图中存在的数据点。 如何避免欠拟合
拟合优度“拟合优度”这个术语取自统计学,机器学习模型的目标是实现拟合优度。在统计建模中,它定义了结果或预测值与数据集的真实值匹配的紧密程度。 拟合良好的模型介于欠拟合和过拟合模型之间,理想情况下,它能以 0 误差进行预测,但实际上很难实现。 当我们训练模型一段时间时,训练数据的误差会下降,测试数据也是如此。但是,如果我们长时间训练模型,那么模型性能可能会由于过拟合而下降,因为模型也会学习数据集中的噪声。测试数据集中的误差开始增加,因此,在误差开始增加之前的那个点是一个好点,我们可以在这里停止以获得一个好的模型。 还有另外两种方法可以为我们的模型获得一个好点,那就是重采样方法来估计模型准确性以及验证数据集。 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
