泰坦尼克号 - 机器学习灾难2025年3月17日 | 阅读18分钟  1912年泰坦尼克号沉没的悲剧事件,是历史上令人痛心的海上灾难。除了悲剧本身,与泰坦尼克号相关的数据集已成为从事数据科学和机器学习领域人士的重要资源。在接下来的探讨中,我们将深入研究泰坦尼克号数据集作为机器学习领域宝贵平台的重要性,它为那些对机器学习感兴趣的人提供了宝贵的经验,如数据准备、特征处理和预测建模等方面。 它被认为是一个初学者数据集,因此我们将非常基础地处理数据集。 数据集描述训练数据集是构建机器学习模型的基础。在这个训练数据集中,提供了每位乘客的结果,通常称为“真实值”。模型的构建依赖于各种属性或“特征”,例如乘客的性别和舱位等级。此外,还存在特征工程的可能性,允许创建新的属性。 数据词汇表
特征详述
挑战泰坦尼克号数据集的挑战在于根据年龄、性别、舱位等级等各种特征预测哪些乘客在这场灾难中幸存下来。这个挑战属于监督学习的范畴,因为我们有训练集的标记数据,并且我们的目标是预测测试集的标签。 代码实现
首先,我们将看看数据集中有哪些特征。 输出  看起来我们的数据集有很多属性。那么我们需要对这些特征进行分类,比如哪些是分类特征,哪些是数值特征。 分类特征:这些值将实例分类到可比较的实例组中。分类特征包括名义、顺序、比率或区间值。这有助于选择合适的可视化方法等。 分类:Survived、Sex和Embarked。顺序:Pclass。 数值特征:这些值在不同实例之间变化。数值特征包括离散、连续或时间序列值。这有助于确定合适的绘图进行可视化等。 连续:Age、Fare。离散:SibSp、Parch。 输出  混合数据类型指的是单个特征中同时包含数字和字母数字数据。这些实例是实现预期目标进行纠正的潜在候选者。我们的数据集中确实存在混合数据类型。 在这里,船票信息包含数字和字母数字数据类型的组合,而船舱数据仅包含字母数字字符。 在大型数据集中分析特征中的错误和拼写错误可能更具挑战性。然而,检查较小数据集的样本子集可能很容易地揭示需要纠正的特征。 在这里,如果您仔细观察,“Name”属性可能包含不准确之处或拼写错误,因为使用了各种格式来表示姓名。这些格式包括称谓、括号和引号,通常用于备用或缩写名称。 输出  输出  在数据集中,“Cabin”、“Age”和“Embarked”属性显示了一系列空值,按出现次数从高到低排序。 有七个特征具有整数或浮点数据类型,在测试数据集中,这个数量减少到六个。此外,有五个特征表示为字符串或对象。 输出  让我们看看数值特征的各种分布
输出  让我们看看分类特征的各种分布
制定假设我们将建立基于迄今为止进行的数据分析得出的假设。我们还可能寻求进一步证实这些假设,然后再做出必要的决定。以下是假设:
透视特征通过创建交叉引用不同特征的透视表,我们可以快速评估特征之间的相关性。但是,此分析目前仅限于没有缺失值的特征。此外,谨慎的做法是专门针对属于分类(Sex)、顺序(Pclass)或离散(SibSp、Parch)类型的特征进行此分析。 输出  输出  输出  输出 
我们现在可以继续通过使用可视化来分析数据来验证某些假设。 数值特征之间的相关性我们将通过理解数值特征与我们期望的结果(Survived)之间的相关性来开始我们的分析。 输出  仔细检查数据后,注意到以下几点:
因此,随后做出了以下决定:
数值特征与顺序特征之间的相关性我们可以合并几个特征来通过单一可视化检测相关性。此方法适用于具有数值的数值和分类特征。 输出  仔细检查数据后,注意到以下几点:
根据这些观察,做出了以下决定:
分类特征之间的相关性接下来,我们将建立分类属性与我们解决方案目标之间的相关性。 输出  仔细检查数据后,注意到以下几点:
因此,随后做出了以下决定:
分类特征与数值特征之间的相关性我们还可以考虑检查分类特征(具有非数值值的特征)与数值特征之间的潜在相关性。例如,我们可以探索 Embarked(分类非数值特征)、Sex(另一个分类非数值特征)、Fare(数值连续特征)和 Survived(分类数值特征)之间的相关性。 输出  仔细检查数据后,注意到以下几点:
因此,随后做出了以下决定:
数据整理,也称为数据捣碎或数据预处理,是清理、转换和组织原始数据以获得更结构化和可用格式进行分析的过程。它涉及处理缺失值、删除重复项、格式化数据以及合并来自不同来源的数据等各种任务。数据整理可确保数据准确、一致并为进一步分析做好准备,从而使整个数据分析过程更顺畅、更有效。 丢弃特征通过删除特征,我们处理的是较少的数据点。这加快了模型的性能并简化了分析。 我们打算删除 Cabin 和 Ticket 特征。 输出  创建新特征我们旨在检查 Name 特征是否可以被操纵以提取称谓,然后评估称谓与生存率之间的联系。将在决定删除 Name 和 PassengerId 特征之前进行此分析。 现在,我们将使用正则表达式提取 Title 特征。正则表达式模式 (\w+\.) 识别 Name 特征中以点字符开头的第一个单词。通过使用 expand=False 标志,我们得到一个 DataFrame 作为输出。 输出 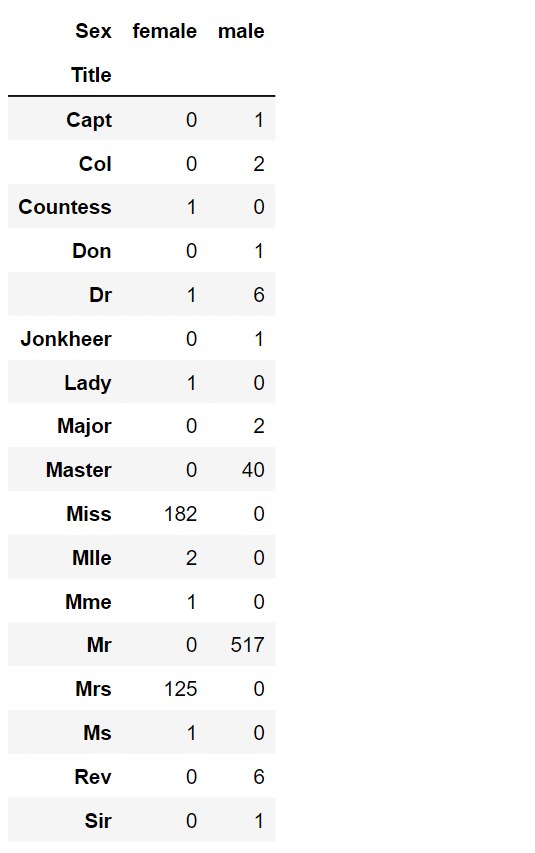 仔细检查数据后,注意到以下几点:
因此,随后做出了以下决定:
我们可以选择用一个更常见的名称替换许多称谓,或者将它们归类为“Rare”。 输出  我们可以将分类的称谓转换为顺序值。 输出  我们现在可以放心地从数据集中删除 Name 特征。此外,数据集中不需要 PassengerId 特征。 输出  转换分类特征我们可以继续将包含字符串值的特征转换为数值特征,因为大多数模型算法都需要这种格式。此转换对于完成特征填充目标也至关重要。为了启动此过程,我们将 Sex 特征转换为名为 Gender 的新特征,其中 female 对应 1,male 对应 0。 输出  连续特征现在,我们需要开始估计和填充具有缺失或空值的特征。让我们从 Age 特征开始。 我们可以考虑三种方法来填充数值连续特征的缺失值:
方法 1 和 3 都可能在我们的模型中引入随机波动,导致多次运行结果不同。因此,我们将选择方法 2 作为首选。 输出  我们将开始创建一个空数组来保存估算的 Age 值,这些值将由 Pclass 和 Gender 的组合确定。 输出  接下来,我们将循环遍历 Gender(0 或 1)和 Pclass(1、2、3)以计算六种可能组合的估算 Age 值。 输出  我们将建立年龄分组,并评估它们与 Survived 的相关性。 输出  我们将用与这些年龄分组相对应的顺序数字替换 Age 值。 输出  我们不能删除 AgeBand 特征。 输出  通过现有特征生成新特征我们可以选择通过合并 Parch 和 SibSp 来生成一个名为 FamilySize 的新属性。然后,这将允许我们从数据集中删除 Parch 和 SibSp。 输出  我们有机会生成一个称为 IsAlone 的附加属性。 输出  我们应该删除 Parch、SibSp 和 FamilySize 属性,而是考虑 IsAlone 特征。 输出  我们还可以通过结合 Pclass 和 Age 来生成一个合成属性。 输出  分类特征Embarked 特征由 S、Q 和 C 值表示,表示登船港口。我们的数据集中有两个实例在此特征中存在缺失值。我们可以方便地用最频繁的出现次数替换这些空白。 输出  输出  分类到数值我们可以通过将 EmbarkedFill 特征转换为名为 port 的新数值特征来继续。 输出  我们无法创建 FareBand。 输出  使用 FareBand 类别将 Fare 特征转换为顺序值。 输出  建模现在我们可以开始训练模型并为我们期望的解决方案进行预测了。我们有超过 60 种预测建模算法可供选择。然而,为了简化我们的选择过程,考虑问题的性质和特定的解决方案要求很重要。在我们的案例中,我们正在处理分类和回归问题。我们的目标是建立输出(乘客是否生存)与各种其他变量或特征(如性别、年龄和登船港口)之间的关系。这属于监督学习的范畴,因为我们正在使用提供的数据集来训练模型。基于这些标准——监督学习结合分类和回归——我们可以将选项缩小到几个合适的模型。这些包括:
RVM(相关向量机) 输出  逻辑回归逻辑回归在分析早期就很有价值。它通过估计概率来评估分类因变量(特征)与一个或多个自变量(特征)之间的联系,这些概率通过逻辑函数估计,代表累积逻辑分布。 输出  我们可以使用逻辑回归来验证我们关于特征创建和填充目标的假设和决策。这可以通过计算决策函数中的特征系数来实现。 正系数会放大响应的对数几率(并随后提高概率),而负系数会减小响应的对数几率(并因此降低概率)。
输出  SVM支持向量机 (SVM) 是监督学习中的模型,配有相应的学习算法,用于分类和回归分析。当提供一组标记为两个类别之一的训练样本时,SVM 训练算法会构建一个模型,将新的测试样本分配到这两个类别之一。此特性将 SVM 分类为非概率二元线性分类器。 输出  K-近邻在模式识别领域,k-近邻算法(缩写为 k-NN)是一种无特定参数的方法,常用于分类和回归任务。该方法通过确定样本的类别来确定其类别,该类别是基于其附近实例的集体意见。样本被分配到其 k 个最近邻中出现次数最多的类别(其中 k 是正整数,通常较小)。当 k 等于 1 时,该项直接分配给最近邻的类别。 输出  朴素贝叶斯朴素贝叶斯分类器属于一类简单的概率分类器,它们使用贝叶斯定理,同时假设特征之间存在很强的(朴素的)独立性。这些分类器以其出色的可扩展性而闻名,因为它们所需的参数数量与给定学习场景中的变量(特征)数量呈线性增长。 输出  感知器该模型使用决策树作为预测模型,该模型将特征(树分支)映射到目标值的结论(树叶)。目标变量可以取有限集合值的树模型称为分类树;在这些树结构中,叶子代表类标签,分支代表导致这些类标签的特征的组合。可以取连续值(通常是实数)的目标变量的决策树称为回归树。 输出  线性 SVM输出  随机梯度下降输出  决策树该模型使用决策树作为预测工具,该工具建立特征(如树的分支)与目标值(由树叶表示)的结论之间的联系。当目标变量具有有限的值范围时,树结构被称为分类树。在这些结构中,类标签位于叶子上,而分支代表与这些类标签对应的特征组合。另一方面,如果目标变量可以具有连续值(通常是实数),则生成的决策树称为回归树。 输出  随机森林随机森林是广泛采用的技术之一。它们是一种用于分类和回归任务的集成学习方法。该方法涉及在训练期间创建许多决策树(n_estimators=100),然后确定来自单个树的预测结果的类别模式(用于分类)或平均预测(用于回归)。 输出 模型置信度得分是迄今为止评估的所有模型中最高的。 模型评估我们现在可以评估和比较我们所有模型的性能,以确定我们任务的最佳模型。尽管决策树和随机森林产生相同的分数,但我们选择随机森林,因为它能够减轻决策树过度适应其训练数据的倾向,这种现象称为过拟合。 输出  我们选择随机森林而不是决策树,因为它克服了过拟合的缺点。 结论泰坦尼克号数据集已从历史性的悲剧事件记录演变为学习和实践机器学习技术的宝贵工具。它提供了实践机会来探索数据预处理、特征工程、探索性数据分析、模型构建和评估。有抱负的数据科学家和机器学习爱好者可以通过泰坦尼克号 - 从灾难中学习机器学习竞赛,更深入地理解真实世界数据分析所涉及的复杂性和挑战。 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
