机器学习中的客户细分2025年6月24日 | 阅读12分钟  客户细分是通过将客户群划分为在营销方面具有某些相似之处的个体群体来完成的,例如年龄、性别、兴趣和消费习惯。它使公司能够通过量身定制的促销、产品或服务来定位特定群体,这些促销、产品或服务最有可能引起他们的共鸣。机器学习已成为自动化客户细分过程的流行工具,提供了一种更有效的方式来识别客户数据中的模式和关系。 使用机器学习进行客户细分的几种不同方法,包括:-
机器学习用于客户细分的优势
现在,我们将对杂货店数据库中的客户记录执行无监督数据聚类。 导入库加载数据输出  数据清理在此,我们将执行以下任务
为了全面了解这些程序,我们将清理数据集。让我们检查数据中包含的信息。 输出  我们可以从上述输出中推断并注意到以下几点
我们将首先删除缺失收入值的行。 输出  下一步是根据“Dt Customer”创建一个特征,该特征显示客户使用公司数据库的注册用户有多长时间。但为了简单起见,我们将使用该值相对于记录中最新的客户。 因此,我们必须比较最新和最早的记录日期才能获得这些值。 输出  输出  创建一个特征(“客户时长”),该特征计算客户与最后记录日期相比已在该公司购物的天数。 为了进一步了解数据,我们现在将调查类别特征中的独特值。 输出  我们将在下一部分执行以下过程来生成一些新特征
现在我们有了一些附加特征,让我们来看看数据的统计信息。 输出  上述统计数据表明,平均收入和年龄以及最高收入和年龄存在一些差异。 请注意,最高年龄为 128 岁,因为数据已过时,我们计算的最高年龄是今天(即 2021 年)。 我们需要从更广泛的角度来看待这些事实。我们将绘制一些选定特征的图。 输出 部分选定特征的关系图:数据子集 <Figure size 800x550 with 0 Axes>  显然,收入和年龄特征包含一些异常值。数据中的异常值将被删除。 输出  现在让我们检查特征之间的关系。(此时,排除分类特征) 输出 <AxesSubplot: >  新特征已到位,数据相当干净。我们将继续进行下一阶段。具体来说,数据准备。 数据预处理在此部分,我们将对数据进行预处理,以便进行聚类程序。 数据使用以下过程进行预处理
输出  输出  输出  输出  降维降维是机器学习和数据科学中一种用于减少数据集中特征或维度数量的技术,同时尽可能多地保留信息。目标是在保留其结构和变量之间关系的同时简化数据。 主成分分析 (PCA) 是一种统计技术,用于分析复杂数据集的结构,例如高维数据集。它用于识别数据中的模式,然后可以用来降低数据的维度,使其更容易可视化和解释。 本节的后续操作
输出  输出  聚类现在将使用凝聚聚类来实现聚类。凝聚聚类是一种分层聚类技术。直到达到适当数量的簇,样本才会被合并。 聚类的步骤
输出  <AxesSubplot: title={'center': 'KMeans Clustering 的失真度肘部图'}, xlabel='k', ylabel='失真度分数'> 根据上面的单元格,四个簇将是此数据集的最佳选择。为了获得最终簇,我们将然后拟合凝聚聚类模型。 让我们看看簇的 3D 分布以研究生成的簇。 输出  评估模型由于此聚类是无监督完成的,因此我们的模型无法进行评估或评分,因为它缺少标记的特征。本节的目标是检查已形成的簇中的模式并确定它们的性质。 为此,我们将使用探索性数据分析来查看在簇的背景下查看数据并做出判断。 输出  这些簇似乎分布相当均匀。 输出  簇模式显示在收入与支出图中。
我们将检查的下一个是簇根据数据中不同商品的具体分布。如下:葡萄酒、水果、肉类、鱼类、糖果和黄金。 输出  从上面的图可以看出,簇 1 是我们最大的客户群,紧随其后的是簇 0。我们可以研究每个簇正在投入的重点营销方法。 接下来,让我们看看我们过去的活动表现如何。 输出  这些活动尚未获得大量回应。通常只有很少的参与者。此外,没有任何一个部分可以包含所有这五项。也许需要设计更完善、更有针对性的促销活动来提高销量。 输出  活动失败了,但交易成功了。第 0 组和第 3 组取得了最好的结果。尽管我们的大客户之一簇 1 对这些协议不太感兴趣。似乎没有什么能强烈吸引簇 2。 输出 <Figure size 800x550 with 0 Axes>  <Figure size 800x550 with 0 Axes>  <Figure size 800x550 with 0 Axes>  <Figure size 800x550 with 0 Axes>  <Figure size 800x550 with 0 Axes> 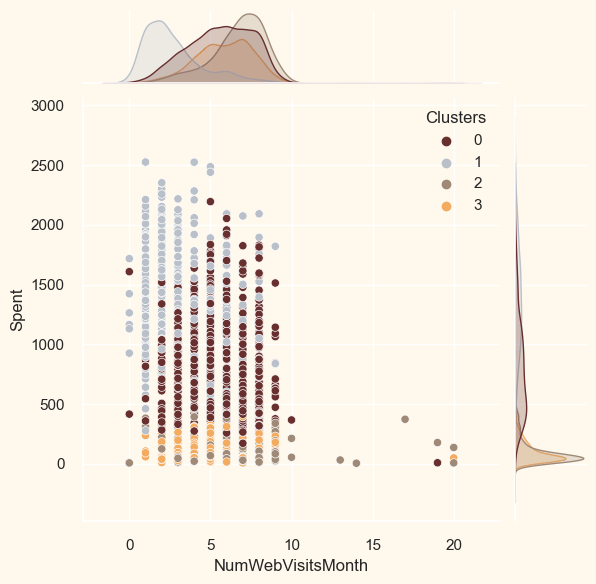 剖析现在簇已经形成并且它们的购买模式已经检查完毕。让我们来看看这些簇中的每个个体。为了确定谁是我们的明星客户,谁需要零售店营销人员的进一步关注,我们将对已开发的簇进行画像。 为了做出决定,鉴于客户所在的簇,我们将绘制一些指示其个人特征的方面。我们将根据结果得出结论。 输出: <Figure size 800x550 with 0 Axes>  <Figure size 800x550 with 0 Axes>  <Figure size 800x550 with 0 Axes>  <Figure size 800x550 with 0 Axes>  <Figure size 800x550 with 0 Axes>  <Figure size 800x550 with 0 Axes>  <Figure size 800x550 with 0 Axes>  <Figure size 800x550 with 0 Axes>  <Figure size 800x550 with 0 Axes> 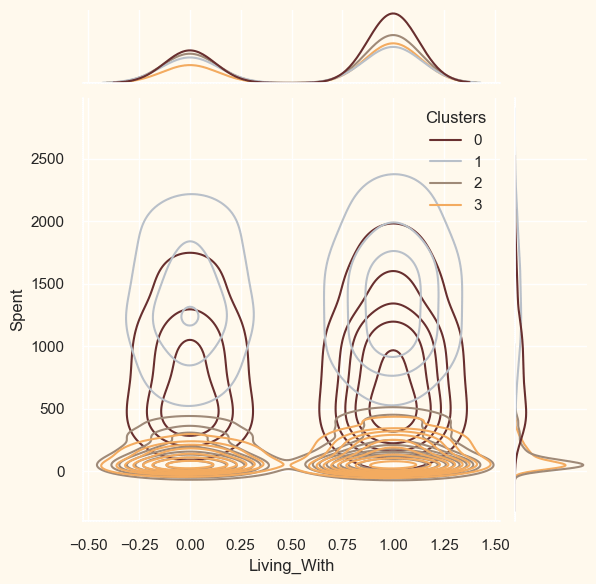 簇号 0
簇号 1
簇号 2
簇号 3
已执行无监督聚类。使用了降维和凝聚聚类。我们创建了四个簇,并利用它们根据客户的家庭构成、收入水平和消费习惯对客户进行画像。这可以应用于创建更好的营销计划。 总之,客户细分是营销策略的一个关键方面,而机器学习已成为自动化该过程的日益流行的工具。通过使用机器学习算法处理海量客户数据,公司可以快速识别新趋势和模式,通过量身定制的促销活动定位特定客户细分,并做出更明智的营销决策。凭借其实时处理数据、无需手动分析以及随着时间的推移不断改进的能力,机器学习是客户细分的一个强大工具。 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
