自动编码器2025年3月17日 | 阅读16分钟  自动编码器是一种神经网络,它学习输入数据的稀疏表示。换句话说,一旦在充分的训练数据上进行训练,自动编码器就可以用来生成输入数据点的压缩副本,这些副本保留了输入的大部分信息(特征),但只使用了少得多的信息比特。 自动编码器是一种神经网络,它包含三个组成部分:编码函数(将数据转换为一个更简单的空间,例如一个节点数量少于输入层的隐藏层),解码函数(反转这个过程,例如一个节点数量与输入层相同的输出层),以及一个距离度量(将损失衡量为原始输入与学习表示之间的距离)。受限玻尔兹曼机是第一种自动编码器,它们在深度学习历史上的重要性足以拥有自己的名称。 自动编码器是与更简单的变量压缩算法(如 PCA 和 LDA)相对应的神经网络。自动编码器通常用于深度学习应用中的预训练,它涉及提前为神经网络设置“正确”的权重,以便算法不需要像从完全随机的权重开始时那样努力工作才能收敛。实际上,更快速的收敛算法的发展已经消除了预训练的必要性和价值。 因此,自动编码器已不再用于前沿的深度学习研究。在商业应用中,它们也无法超越更简单的(通常是信息论的)压缩技术,如 JPEG 和 MG3。它们现在主要用作高维数据在输入到 T-SNE 算法之前的预处理步骤。 自动编码器架构典型的自动编码器架构包含三个关键组成部分
一个高度精调的自动编码器模型应该能够重建在第一层输入的相同输入。 自动编码器的工作原理让我们来探索自动编码器背后的数学原理。自动编码器的主要思想是学习高维输入的低级表示。让我们尝试通过一个例子来理解编码过程。考虑一个数据表示空间(用于表示数据的 N 维空间),并考虑由两个变量 x1 和 x2 表示的数据点。数据流形是在数据表示空间中真实数据存在的区域。 输出 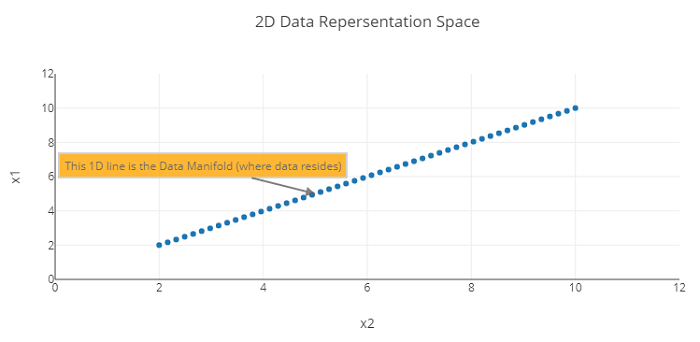 现在我们使用两个维度来表示这些数据:X 和 Y。然而,这个空间的维度可以减小到更低的维度,例如 1D。如果我们能够定义以下内容
那么线上任意一点,例如 B,都可以通过从 A 点开始的距离“d”和角度 L 来表示。 输出   但是,这里关键的问题是,可以用什么逻辑或规则来根据 A 和角度 L 来表达点 B?答案很简单:没有固定的方程,但无监督学习过程可以产生最好的方程。简单来说,学习过程就是一个将 B 转换为 A 和 L 的公式或方程。让我们从自动编码器的角度来看待这个问题。 考虑没有隐藏层的自动编码器;输入 x1 和 x2 被解码为较低的表示 d,然后 d 被投影回 x1 和 x2。 现在我们将探讨稀疏自动编码器、堆叠自动编码器和变分自动编码器。我们还将通过使用 TSNE 将自动编码器的潜在编码映射到二维来可视化它们。这将帮助我们识别数据中的唯一簇。 代码 导入库读取数据集输出  堆叠自动编码器它是一种神经网络,由许多层自动编码器堆叠而成。自动编码器是用于学习特征和降维的无监督学习算法。 输出   我们将从测试数据中进行重建 输出  现在,我们将潜在表示映射到二维。 输出  它重建得很好,但我们可以添加卷积来提高质量。首先,我们将通过创建稀疏自动编码器来添加正则化。这种正则化可以应用于编码层。 稀疏自动编码器它是一种神经网络,其功能类似于常规自动编码器,但具有额外的约束,以在学习的表示中生成稀疏性。稀疏自动编码器用于特征学习和降维任务,目标是学习输入数据的紧凑且稀疏的表示。 在稀疏自动编码器中,我们通过向中间层的激活添加 L1 惩罚来限制中间层的激活稀疏。这意味着——中间层的许多激活将为零——自动编码器将被迫仅将非零值分配给数据最重要的属性。 输出   输出  现在我们将通过将 TSNE 应用于潜在表示来查看自动编码器编码的潜在表示。 输出  使用 CNN 构建自动编码器输出  输出  现在我们将可视化数据的低维表示——使用编码器的输出并应用 TSNE。 输出  簇似乎非常清晰。4 的数字离 9 的数字相当近,这很有道理,因为它们的顶部是相似的。同样,9 和 7 的数字也显得接近,这也有道理,因为它们的结构相似。因此,我们的隐藏表示是有意义的。 另一个卷积自动编码器(使用不同的滤波器)输出  输出  稀疏自动编码器 - 使用卷积输出  输出  4 的数字离 9 的数字相当近,这很有道理,因为它们的顶部是相似的。同样,9 和 7 的数字也显得接近,这也有道理,因为它们的结构相似。因此,我们的隐藏表示是有意义的。 去噪自动编码器目标是用噪声污染训练数据,然后使用自动编码器对其进行恢复。在此方法中,自动编码器学会对数据进行去噪,从而使其能够理解数据的关键属性。 使用随机噪声去噪输出  输出  输出  我们观察到 9、7 和 4 之间的重叠,正如我们之前描述的。我们还看到 2 和 7 之间有轻微的重叠,这是合理的。去噪使神经网络能够正确地编码输入中最关键的方面。由于数据有噪声,因此无法依赖不重要的特征。 去噪自动编码器不仅通过关注数据最相关的方面来改进降维,而且由于它们经过有噪声数据的训练以恢复原始数据,因此还可以用于数据去噪。 使用 Dropout 去噪在这里,我们将 dropout 应用于输入像素,并让网络重建它们。这是另一种类型的去噪自动编码器。我们期望在此过程结束时,网络将学会如何重建缺失的像素。 输出  输出  去噪自动编码器改善了簇之间的区分度。它显示了簇之间的重叠,例如 4、9 和 3、8 之间的重叠,这是合理的。 生成建模我们最初构建的自动编码器作为生成模型的性能不佳。因此,如果我们从潜在空间中采样随机向量,我们很可能会得到一个看起来不像 0-9 中任何数字的图像。常规自动编码器在执行异常检测方面效果很好,但作为生成模型效果不佳。 要构建一个好的生成模型,我们需要一个变分自动编码器。 输出   让我们存储训练数据中存在的潜在空间的统计特性。 输出  正如我们所见,自动编码器作为生成模型的性能不佳,因为生成的虚假图像看起来不自然。然而,我们可以看到它捕捉了大致的轮廓。 变分自动编码器 (VAE)变分自动编码器更适合生成建模。我们可以利用它们来创建新数据。正如我们将看到的,VAE 创建的数据看起来会更逼真。 输出   输出  正如我们所见,变分自动编码器生成的这些图像比通过常规自动编码器生成的图像看起来更好。 下一个主题使用机器学习进行猫分类 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
