广度优先搜索 (BFS) 算法2025 年 4 月 20 日 | 7 分钟阅读 在本文中,我们将讨论数据结构中的 BFS 算法。广度优先搜索是一种图遍历算法,它从根节点开始遍历图,并探索所有相邻节点。然后,它选择最近的节点并探索所有未探索的节点。在使用 BFS 进行遍历时,图中的任何节点都可以被视为根节点。 遍历图的方法有很多种,但其中 BFS 是最常用的方法。它是一种递归算法,用于搜索树或图数据结构的所有顶点。BFS 将图的每个顶点分为两类 - 已访问和未访问。它选择图中的一个节点,然后访问与所选节点相邻的所有节点。 BFS 算法的应用广度优先算法的应用如下:
算法BFS 算法探索图的步骤如下: 步骤 1: 将 G 中每个节点的 STATUS 设置为 1(就绪状态) 步骤 2: 将起始节点 A 入队并将其 STATUS 设置为 2(等待状态) 步骤 3: 重复步骤 4 和 5,直到 QUEUE 为空 步骤 4: 将节点 N 出队。处理它并将其 STATUS 设置为 3(已处理状态)。 步骤 5: 将 N 的所有处于就绪状态(其 STATUS = 1)的邻居入队并设置 它们的 STATUS = 2 (等待状态) [循环结束] 步骤 6: 退出 BFS 算法示例现在,让我们通过一个示例来了解 BFS 算法的工作原理。在下面的示例中,有一个具有 7 个顶点的有向图。 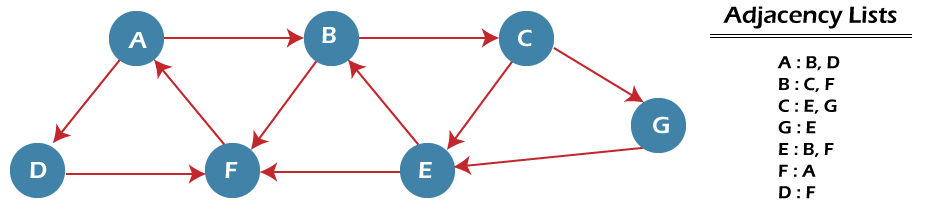 在上面的图中,可以使用 BFS 找到最短路径“P”,它将从节点 A 开始到节点 E 结束。该算法使用两个队列,即 QUEUE1 和 QUEUE2。QUEUE1 包含所有要处理的节点,而 QUEUE2 包含所有已处理并从 QUEUE1 中删除的节点。 现在,让我们从节点 A 开始检查图。 步骤 1 - 首先,将 A 添加到 queue1,将 NULL 添加到 queue2。 步骤 2 - 现在,从 queue1 中删除节点 A 并将其添加到 queue2。将节点 A 的所有邻居插入 queue1。 步骤 3 - 现在,从 queue1 中删除节点 B 并将其添加到 queue2。将节点 B 的所有邻居插入 queue1。 步骤 4 - 现在,从 queue1 中删除节点 D 并将其添加到 queue2。将节点 D 的所有邻居插入 queue1。节点 D 的唯一邻居是 F,因为它已插入,所以不会再次插入。 步骤 5 - 从 queue1 中删除节点 C 并将其添加到 queue2。将节点 C 的所有邻居插入 queue1。 步骤 5 - 从 queue1 中删除节点 F 并将其添加到 queue2。将节点 F 的所有邻居插入 queue1。由于节点 F 的所有邻居都已存在,我们将不会再次插入它们。 步骤 6 - 从 queue1 中删除节点 E。由于它的所有邻居都已添加,所以我们不会再次插入它们。现在,所有节点都已访问,并且目标节点 E 出现在 queue2 中。 BFS 算法的复杂度BFS 的时间复杂度取决于用于表示图的数据结构。BFS 算法的时间复杂度为 O(V+E),因为在最坏的情况下,BFS 算法会遍历每个节点和每条边。在图中,顶点数为 O(V),而边数为 O(E)。 BFS 的空间复杂度可以表示为 O(V),其中 V 是顶点的数量。 BFS 算法的实现现在,让我们看看 BFS 算法在 Java 中的实现。 在此代码中,我们使用邻接列表来表示我们的图。在 Java 中实现广度优先搜索算法使得处理邻接列表变得容易得多,因为我们只需要在节点从队列头部(或开始)出队后,遍历连接到每个节点的节点列表一次。 在此示例中,我们用于演示代码的图如下:  输出  结论在本文中,我们讨论了广度优先搜索技术及其示例、复杂度和在 Java 编程语言中的实现。在这里,我们还看到了 BFS 的实际应用,这表明它是一个重要的数据结构算法。 那么,关于这篇文章就到这里。希望它能对您有所帮助和启发。 BFS 算法的 MCQ 练习问题 1: 以下哪项准确描述了 BFS 算法的初始步骤?
答案:B 解释: 在广度优先搜索 (BFS) 计算中,起始步骤是将起始节点入队并将其标记为“等待”或“已访问但未完全探索”。这表明节点已被找到并添加到队列中,但其相邻节点尚未被探索。 问题 2: BFS 通常被优先用于在无权重图中寻找最短路径的主要原因是什么?
答案:B 解释: BFS 在移动到另一深度级别的节点之前,会调查当前深度级别的所有节点,这保证了在无权重图中以边数计算的最短路径。 问题 3: 在 BFS 的上下文中,“已处理状态”表示什么?
答案:B 解释: 在 BFS 中,当一个节点出队时,它被标记为已准备好,表明其所有邻居都已入队。 问题 4: 布尔数组“nodes”在 BFS 的 Java 实现中扮演什么角色?
答案:C 解释: 布尔数组“nodes”用于跟踪节点是否已被访问,以避免重复处理节点。 问题 5: 关于 BFS 算法的时间复杂度,哪个说法是正确的?
答案:D 解释: BFS 的时间复杂度为 O(V + E),因为它访问每个顶点一次,并遍历每条边一次。 下一主题DFS 算法 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
