快速排序算法 (附 Python/Java/C/C++ 程序)2025 年 5 月 7 日 | 阅读 12 分钟 快速排序是一种利用分治技术的排序算法。它选择一个基准元素,并将其放在已排序数组的适当位置。 分治法是一种将算法分解为子问题,然后解决子问题,并将结果组合起来以解决原始问题的方法。
步骤:步骤 1:选择基准元素。通常选择第一个、最后一个或中位数元素作为基准元素。 步骤 2:对数组进行分区。为此,请围绕基准元素重新排列数组的元素。分区后,基准元素左侧的元素(左子数组)小于基准元素,基准元素右侧的元素(右子数组)大于基准元素。 步骤 3:对左子数组和右子数组重复上述步骤。这可以通过递归完成。当子数组只剩下一个元素时,递归停止。因为单个元素已经是排序好的。 算法快速排序算法的工作原理实现快速排序的简单步骤如下。 步骤 1:选择基准元素。通常选择第一个、最后一个或中位数元素作为基准元素。在本例中,我们选择最后一个元素作为基准。此外,取两个指针 j 和 k,其中 j 的值为 -1,k 指向数组的第 0 个索引。移动 j 指针,使得 j 指针指向的元素及其左侧的元素都小于基准元素。  步骤 2:将 a[k],即 19,与基准元素进行比较。我们看到 a[k] > 基准元素。因此,将 k 增加 1。现在,k 指向第 1 个索引。  步骤 3:将 a[k],即 4,与基准元素进行比较。我们看到 a[k] < 基准元素。因此,将 j 增加 1。现在,j 指向第 0 个索引。  步骤 4:交换 a[j] 和 a[k],并将 k 增加 1。现在,k 指向第 2 个索引。  步骤 5:将 a[k],即 13,与基准元素进行比较。我们看到 a[k] < 基准元素。因此,将 j 增加 1。现在,j 指向第 1 个索引。  步骤 6:交换 a[j] 和 a[k],并将 k 增加 1。现在,k 指向第 3 个索引。  步骤 7:将 a[k],即 18,与基准元素进行比较。我们看到 a[k] > 基准元素。因此,将 k 增加 1。现在,k 指向第 4 个索引。  步骤 8:将 a[k],即 10,与基准元素进行比较。我们看到 a[k] < 基准元素。因此,将 j 增加 1。现在,j 指向第 2 个索引。  步骤 9:交换 a[j] 和 a[k],并将 k 增加 1。现在,k 指向第 5 个索引。  步骤 10:将 a[k],即 10,与基准元素进行比较。我们看到 a[k] < 基准元素。因此,将 j 增加 1。现在,j 指向第 3 个索引。  步骤 11:交换 a[j] 和 a[k],并将 k 增加 1。现在,k 指向第 6 个索引。  步骤 12:将 a[k],即 15,与基准元素进行比较。我们看到 a[k] < 基准元素。因此,将 j 增加 1。现在,j 指向第 4 个索引。  步骤 13:交换 a[j] 和 a[k]。由于 k 指向最后一个元素,因此进一步的检查和交换停止在此处。请注意,j 索引左侧的所有元素以及 j 索引处的元素都小于基准元素。 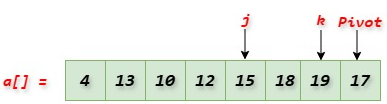 步骤 14:将 a[j + 1] 与基准元素交换(交换 18 和 17)。  我们看到基准元素已放置在排序数组的正确位置。 步骤 15:根据基准元素将数组划分为左子数组和右子数组。位于基准元素左侧的元素是左子数组的一部分,位于基准元素右侧的元素是右子数组的一部分。  步骤 16:对左子数组和右子数组重复所有步骤。  Python/Java/C/C++/C# 中的快速排序实现复杂度分析
空间复杂度:空间复杂度为 **O(n)**,因为递归调用堆栈,其中 n 是输入数组中元素的总数。 快速排序的应用
快速排序的优点
快速排序的缺点
结论由于其速度和简单性,快速排序是最广泛使用和最高效的排序算法之一。其原地排序能力与分治方法的结合,使其适用于内存受限的系统和大型数据集。 下一主题归并排序 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
