链表反转17 Mar 2025 | 6 分钟阅读 引言反转链表是计算机技术中的一项基本操作,在许多算法和记录操作任务中扮演着重要角色。链表由一种统计结构组成,其中每个节点都包含一个记录以及对序列中下一个节点的引用或链接,该序列由相互连接的节点组成。要刷新链表,您必须更改这些连接的路径,从而颠倒它们的顺序。 为了理解反转关联表的过程,让我们深入研究其中涉及的关键规范和方法。反转系统可以通过迭代或递归策略来实现。 在迭代系统中,我们切断链表,将每个节点的下一个指针更改为指向其前一个节点。这需要维护三个指针:一个用于当前节点,一个用于前一个节点,一个用于下一个节点。该算法会一直持续,直到整个链表被反转。 另一方面,递归方法利用递归特性来反转关联表。基本情况是到达表的顶部,并且该函数向后工作,因为它从每个递归调用返回时反转链接。 反转链表在优化记录访问模式方面具有实际应用,类似于需要以相反顺序处理因素的算法。它还在不同的编码面试问题中被采用,并作为其他冗余、复杂数据结构操作的重要构建块。 在评估反转算法时,处理边缘情况至关重要,例如空表或只有一个元素的列表。此外,必须记住所选方法的时间和空间复杂度。迭代方法通常具有 O(n) 的时间复杂度,其中 n 是表中突起的数量。同时,由于递归调用堆栈,递归方法的空间复杂度可能会更高。 理解关联表的反转提供了对指针操作的洞察力,并有助于支持人们对基础数据系统的掌握。此外,它还促进了对算法及其性能的更深层次的理解,这是笔记本电脑技术知识和软件程序增强方面的基本天赋。 最终,反转关联表是具有广泛笔记本电脑技术知识应用的初级操作。无论是通过迭代还是递归过程,掌握这个概念都能增强故障排除能力,并为冗余的、高级数据结构操作奠定基础。反转链表所涉及的复杂性有助于全面理解算法、数据系统和高效编码实践。 有两种实现方法 1. 递归方法反转链表的递归方法很简单:首先,我们将链表分成其初始节点和其余的链表元素。接下来,我们通过保持连接来为剩余的链表元素调用递归方法。  递归方法的实现 输出 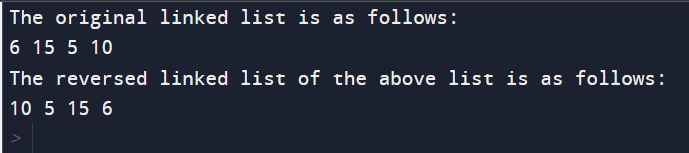 说明 所提供的代码定义了一个易于连接的表实现,其中 Node 类表示字符元素,而并存的 LL (LinkedList) 类处理列表。LL 类包含将元素推送到列表 (push)、使用递归反转链表 (reverse_LL) 以及发布表元素 (printLL) 的方法。 在 Node 类中,每个节点由记录和对集合中下一个节点的引用组成。LL 类通过指向第一个节点的 head 特征进行初始化,该特征最初设置为 None。push 方法在表的开头添加一个新节点,从而相应地简化 head 引用。 代码的核心在于verse_LL方法,这是一个负责反转连接列表的递归函数。它接受参数。Curr 是正在重用的当代节点,而 former 是重用后将成为 Curr 的新下一个节点的节点。基本情况是评估 ultramodern 节点 (curr) 是否为 None,在这种情况下,链表的顶点将被简化为结束重用节点 (former)。否则,它会递归调用自身,将下一个节点 (ne_n) 作为当前节点,并将当前节点 (curr) 变成新的下一个节点 (ne_n)。此方法有效地反转了节点之间的链接。 后置系统充当通过调用带有链表头部的 reverse_LL 来启动反转的包装器。 最终,示例应用程序部分演示了创建连接表、将元素推送到其中、发布唯一列表、反转它,然后发布反转的表。
2. 迭代方法
 输出  说明 所提供的代码定义了一个简单的关联表实现,其中 Node 类表示个人因素,而并存的 LL (LinkedList) 类管理该表。LL 类包含将因素推送到表 (drive)、使用迭代方式反转连接列表 (reverse) 以及发布列表元素 (printLL) 的样式。 在 Node 类中,每个节点包括数据和对集合中下一个节点的引用。LL 类通过指向主节点的 head 特征进行初始化,该特征最初设置为 None。drive 系统在表的开头添加一个新节点,从而相应地简化 head 引用。 代码的核心在于反向系统,这是一个负责反转关联表的迭代点。它独立初始化指南(curr 和 prev)以切断和反转表。同时,循环会一直持续,直到到达列表的末尾。在循环内部,通过简化后置指针来反转节点之间的链接。prev 指针保持表的反转部分的轨迹,而 curr 指针向前移动。覆盖整个列表后,head 被简化为指向新的第一个节点。 示例应用程序阶段演示了创建关联表、将元素推送到其中、发布原始表、使用后置方法反转它,然后使用 printLL 系统发布反转后的列表。结果是连接列表中唯一因素的逆序。
下一主题最大矩形面积 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
