使用 Hoare 分区法的快速排序2025年03月17日 | 阅读 9 分钟 在本文中,我们将讨论如何使用Hoare分区实现快速排序,其应用以及Hoare分区方案相对于Lomuto分区方案的优势。 快速排序这种排序算法的思想是选择一个元素(枢轴元素)并找到它在数组中的正确位置,确保其左边的元素必须更小,右边的元素必须更大。对左子数组和右子数组递归重复相同的过程,直到数组排序完成。 它在内存使用和时间方面更高效,是一种广泛使用的搜索算法。它采用分治法对数组进行排序。 伪代码Hoare分区方案查尔斯·安东尼·理查德·霍尔爵士开发了快速排序算法,Lomuto和Hoare的分区方案都是他提出的。与Lomuto分区(它使用一个枢轴元素并基于它对数组进行分区)不同,Hoare分区使用两个指针,它们沿相反方向遍历数组,并进行必要的交换直到指针相遇。 这种分区方案减少了交换次数,从而实现了时间高效的性能。其工作原理如下: 伪代码 分区索引左边的元素将小于或等于枢轴。分区索引右边的元素将大于或等于枢轴。 时间复杂度分析平均情况分析 在平均情况下,我们认为分区没有将数组公平地分成两半。我们考虑第一半有1/10的元素,第二半有9/10的元素。 最坏情况分析 当我们传递一个按升序或降序排序的数组时,它的性能会更差。在最坏情况下,分区函数每次都选择最小或最大的元素,导致性能不佳。 空间复杂度分析快速排序算法是一种原地排序算法,不需要额外的空间来存储元素。它需要辅助空间用于递归调用栈。 在最坏情况下,递归调用栈需要 Θ(n) 空间。 下面是递归调用栈的快照  Python 实现输出  说明 我们有一个列表:arr = [10, 2, 16, 22, 35, 17, 26, 3, 9, 13],n = 10。 调用: quickSort(arr, 0, 9) 这里,low = 0 且 high = 9,low 小于 high quickSort()函数调用 hoarePartition(arr, 0, 9)。当它返回分区索引时,quickSort()使用以下参数调用自身:quickSort(arr, low, i) 和 quickSort(arr, i+1, high)。  整个思想在于分区方案。因此,理解Hoare分区方案很重要。您可以在此处找到使用Lomuto分区法的快速排序的简要说明。 现在让我们了解hoarePartition()函数的工作原理。 它选择子数组的第一个元素作为枢轴来比较其他元素。这里,枢轴 = arr[0] = 10,左右指针初始化如下: left = -1 right = 10 然后它开始一个无限循环来遍历数组。 它初始化 left = 0 指针并将其向右移动,直到找到一个大于或等于枢轴的元素。 left = 0 arr[left] = 10 等于枢轴 = 10:由于while条件不满足,它在 left = 0 处中断循环。 然后它初始化 right = 9 并将其向左移动,直到找到一个小于或等于枢轴的元素。 right = 8 arr[right] = 9 小于枢轴 = 10:由于while条件不满足,它在 right = 8 处中断循环。 然后我们检查左指针是否越过右指针。这里,if条件不满足。 然后我们交换 left = 0 和 right = 8 处的元素。  由于左指针小于右指针,它开始下一次迭代。 在第二次迭代中 它交换 left = 2 和 right = 7 处的元素:swap(arr[left] = 16, arr[right] = 3)  在第三次迭代中 左指针停在索引3,arr[left] = 22,右指针停在索引2,arr[right] = 3。 在此迭代中,左指针变得大于右指针,hoarePartition()返回 right = 2。  让我们快速回顾一下其他一些函数调用。 调用:quicksort(arr, 0, 2) 在此调用中,hoarePartition()交换 (9, 3) 并返回 1,并根据需要进行函数调用。 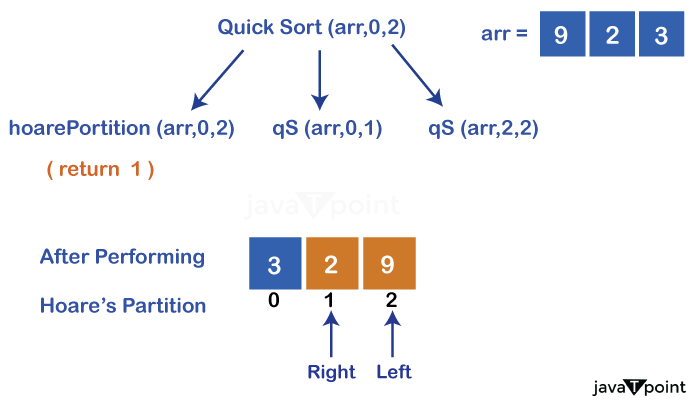 上述递归树展示了如何进行后续函数调用。 调用:quicksort(arr, 3, 9)  在此调用中,hoarePartition()首先交换 (22, 13),然后交换 (35, 10),最后交换 (26, 16) 并返回 6。 这个过程对所有可能的递归调用递归重复,最终数组得到排序。 C++ 实现输出  C 语言实现输出  Hoare分区相对于Lomuto分区的优势Hoare分区相对于Lomuto分区具有多项优势,使其在某些场景下成为首选
然而,与Lomuto分区一样,它也不能保证稳定性。相同元素的顺序可能会改变。 结论快速排序是一种原地排序算法,遵循分治法。它利用了Hoare分区,提供了出色且时间高效的分区。它提高了快速排序算法的性能,导致比Lomuto分区更快的排序时间。快速排序是高效排序大型数据集的流行选择。当稳定性不那么重要时,它优于归并排序。它对缓存友好,因为它对所有数据进行操作,并且所有数据都可以存储在缓存中。 下一个主题最长公共子串 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
