栈和堆的区别2025年4月19日 | 阅读 9 分钟 在理解堆栈和堆数据结构之间的区别之前,我们应该先分别了解堆栈和堆数据结构。 什么是堆栈?堆栈是一种用于组织数据的数据结构。堆栈类似于现实世界中组织物体的方式。现实世界中堆栈的一些例子包括一叠餐盘、一个称为“汉诺塔”的数学谜题,其中包含三个带有多个圆盘的杆,以及一叠网球。堆栈是一个集合,其特性是一个项目或对象必须从一端移除,称为“堆栈顶部”。 它不能被视为一种属性,而应被视为应用于堆栈的约束或限制。换句话说,我们可以说只有堆栈顶部是可访问的,任何项目都可以从堆栈顶部移除或插入。它遵循 LIFO(后进先出)原则,其中最近添加的元素必须首先从堆栈中移除。 堆栈是一个列表或集合,其插入和删除操作都发生在称为堆栈顶部的一端。 操作以下是堆栈 ADT 可用的两个操作:
堆栈的表示堆栈如下图所示:  从上图可以看出,堆栈看起来像一个从一侧打开的容器。它可以在逻辑上表示为一个从一侧打开的容器的三侧图形。上图表示一个空的堆栈,我们假设堆栈为“s”。这是一个整数堆栈。现在我们将对堆栈执行入栈和出栈操作。假设我们要将 2 插入堆栈。入栈操作后,堆栈将显示为:  由于堆栈中只有一个元素,因此元素 2 将位于堆栈顶部。如果要将 1 插入堆栈,堆栈将显示为:  由于元素 1 位于元素 2 的上方,因此元素 1 将被视为堆栈顶部。如果执行出栈操作,则如上所示,最顶部的元素,即 1,将被从堆栈中移除:  什么是堆?堆也是一种数据结构或用于存储全局变量的内存。默认情况下,所有全局变量都存储在堆内存中。它允许动态内存分配。堆内存不由 CPU 管理。堆数据结构可以使用数组或树来实现。 它是一个完全二叉树,满足堆属性条件,其中完全二叉树是所有层都已完全填充,只有最后一层除外。在最后一层,所有节点都尽可能靠左。 指针和动态内存 在这里,我们将研究内存的架构。了解系统如何管理内存以及我们程序员如何访问内存至关重要。在典型的架构中,分配给程序或应用程序的内存分为四个段。内存的一个段存储要执行的指令。内存的另一个段存储全局变量或静态变量。全局变量是在函数外部声明的变量,其生命周期贯穿整个程序。第三个段,即堆栈,用于存储所有函数调用和局部变量。当调用任何函数时,它会在内存中占用一些空间,称为堆栈内存。  让我们通过一个例子来理解堆栈内存。 在上面的代码中,执行从 main() 方法开始。因此,main() 方法将在堆栈中获得内存,如下所示:  当调用 sum() 方法时,控制将转移到 sum() 函数。  sum() 方法调用 square() 方法;因此,square() 方法将在堆栈中获得内存,如下所示:  一旦 square() 方法的 return 语句被执行,控制将返回到 sum() 方法,并且 square() 方法将从堆栈中移除,如下所示:  当 sum() 方法的 return 语句被执行时,控制将返回到 main() 方法,并且 sum() 方法将从堆栈中移除,如下所示:  在 main() 方法中,调用了 printf() 函数,因此它将在堆栈中获得内存,如下所示:  一旦 printf() 语句的执行完成,printf() 和 main() 方法将从堆栈内存中移除,如下所示:  使用堆栈内存存在一些限制。假设操作系统为程序保留了 1MB 的堆栈内存。如果程序不断调用函数,堆栈内存将不足,并导致堆栈溢出。堆栈溢出会导致程序崩溃。因此,我们可以说堆栈内存不会在运行时增长。 堆栈的另一个限制是变量的作用域无法操纵。堆栈上内存的分配和释放由规则设定,即当调用函数时,它会被推入堆栈顶部;当调用 pop() 操作时,元素将从堆栈顶部移除。 堆栈的第三个限制是,如果我们定义大型数据类型(如数组),并且数组的大小未在编译时定义。我们想根据某些参数定义数组的大小,而堆栈无法在运行时定义数组的大小。 因此,为了分配大块内存并将内存保留一段时间,我们可以使用 堆 数据结构。与堆栈数据结构不同,堆内存的大小可以变化,并且在应用程序的整个生命周期中不是固定的。在堆内存中,对于内存的分配和释放没有固定的规则。程序员可以自己手动处理内存。对程序员来说,将堆视为可供使用的免费大片内存,我们可以根据需要使用它。 堆也称为动态内存,使用堆可以被视为动态内存分配。要使用动态内存,我们需要使用一些函数。在 C 语言 中,我们可以使用 malloc() 和 calloc() 来分配内存,并使用 free() 函数来释放内存;而在 C++ 语言 中,我们使用 new 运算符进行分配,使用 delete 运算符进行释放。 让我们通过一个例子来理解动态内存。 上述代码的解释。 首先,我们声明了变量 'a',它在 main() 方法的堆栈帧内分配在堆栈中,如下所示: 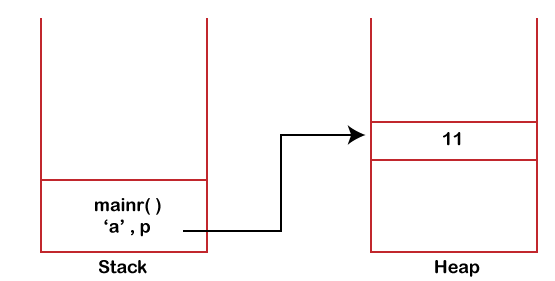 要分配到 堆内存,我们需要使用 malloc() 函数。我们在上述代码中使用了 malloc() 函数,其中传递了 sizeof(int),表示在堆内存中分配了 4 字节的块。该函数返回一个 void 指针,其中包含块的起始地址。'p' 是函数局部的一个指针变量,因此它存储在堆栈中,如下所示:  再次,我们分配了由 'p' 变量指向的新内存块,因此 'p' 不持有先前块的地址。具有值 11 的块是内存的不必要消耗。在堆中,内存不会自动释放,我们必须手动释放内存。因此,在上述代码中,我们使用了 free(p) 函数,其中我们将 'p' 传递给释放 'p' 指向的内存。 堆栈与堆的区别
下一个主题冒泡排序和选择排序的区别 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
