使用堆的时间复杂度17 Mar 2025 | 4 分钟阅读 堆是一种特殊的基于树的数据结构,它符合堆属性。堆在编程和计算机科学应用中包括排序算法和优先级队列。主要有两种堆:
通常,堆被实现为二叉树。在 O(log n) 时间内,其中 'n' 是堆中元素的数量,二叉堆可以有效地处理插入、删除和确定最小或最大元素。 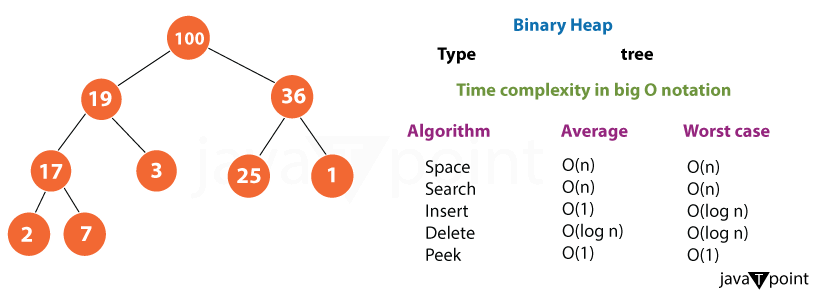 堆的常见用例包括:
使用堆的时间复杂度根据所执行的特定操作,堆数据结构的时间复杂度各不相同。以下是典型的堆操作及其时间复杂度: 
重要的是要记住,这些时间复杂度取决于堆结构保持平衡。如果堆变得不平衡,操作在时间方面可能会变得不那么复杂。此外,堆类型的选择可能会影响代码的实际性能,因为不同的堆类型(例如,二叉堆、斐波那契堆)对于特定操作可能具有略微不同的时间复杂度。 结论总而言之,堆数据结构对于许多计算机科学和编程应用至关重要,因为它们提供了有效组织和处理具有特定特征数据的方法。最大堆和最小堆各自符合其堆特性,为插入、删除和识别极端元素等操作奠定了基础,所有这些都具有明确的时间复杂度。 在设计算法和为给定任务选择最佳数据结构时,理解堆操作所涉及的时间复杂性至关重要。尽管堆是有效的工具,但选择正确的堆变体(例如二叉堆或斐波那契堆)也可以提高代码的效率。 总而言之,堆在计算机科学和编程领域中是很有用的工具,因为它们是适应性强、有效的数据结构,具有广泛的用途。 下一主题双向归并排序 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
