“一个”堆与“那个”堆有什么关系?2025年2月6日 | 阅读7分钟 堆(数据结构)“堆”通常指的是一种叫做堆(通常是基于树的结构)的数据结构。堆主要有两种类型:二叉堆和二项堆。 二叉堆 二叉堆是一种遵循堆属性的二叉树数据结构。它是优先队列的主要应用之一。 最大堆 在最大堆中,节点 i 不是根节点,并且 i 的值小于或等于其子节点的值。峰值元素位于根节点。 最小堆 在最小堆中,对于根节点以外的每个节点,i 的值等于或大于其子节点的值。所需的最大值位于最低级别。 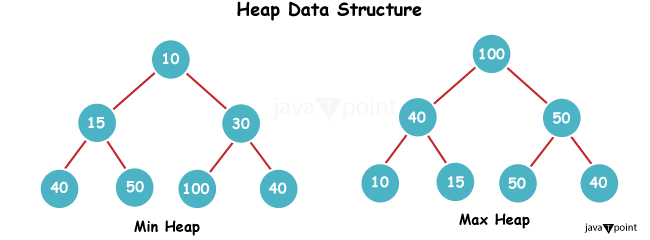 二项堆 二项堆是一种将较小的二项树组合成一个结构的数据结构。它当然与二叉堆互补,并将合并和减小键作为高效操作。二项堆在这些操作上比二叉堆具有更好的摊销时间复杂度。 代码实现输出 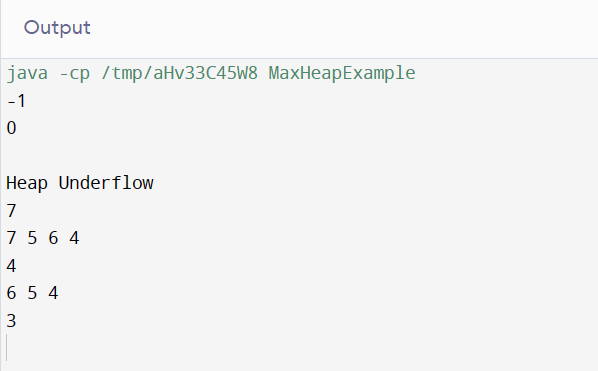 说明 - 堆类:实例变量:堆组件可以存储在数组中。
- 堆化上移(Heapifyup)技术:此方法用于确保在执行 push 操作后维持堆属性。它将新项目放入第一个位置,然后相互比较并交换,必要时进行交换,直到堆属性再次完整。
- 堆化下移(Heapifydown)策略:它有助于在执行 pop 操作后恢复堆属性。它以根组件为基础,然后将其与较大的子节点交换,直到恢复堆属性。
- push 技术:这种技术用于将元素插入堆中。它将元素添加到堆的末尾,然后调用 Heapifyup 来创建堆属性。
- pop 方法:该方法实现从堆中移除根(最大元素)。它首先使用最后一个元素替换根,然后调用 Heapifydown 以确保保留堆条件。
- print_heap 方法:此技术用于显示堆的各个元素。
- top 方法
- 此技术从堆中提取最大(根)元素。
- 初始堆(h)被设置为空。
- 尝试在空堆上使用 pop() 会显示“堆下溢”消息。
- 节点 5 和 7 被推送到队列中,然后打印根节点。
- 另一对元素(6, 4)进入堆,然后显示更新后的堆。
- 打印出堆的大小。
- 执行 pop() 操作,然后打印 pop 之后的堆。
- 输出
- 最后,打印出堆数据结构。
- 该程序使用最大堆,其中根节点具有最大值。
- push、pop、print_heap、size 和 top 等方法提供了与堆交互的功能。
最小堆输出 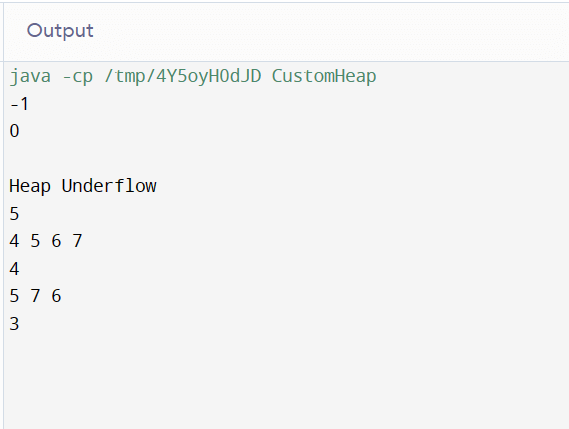 说明 - 类声明:确定一个名为 CustomHeap 的类。
- 实例变量:确定私有数组 heapArraY(用于存储堆组件)和 heapSize(用于跟踪堆的当前大小)。
- 构造函数:初始化 heapArray,大小固定,heapSize 设置为 -1。
- HeapifyUp 策略:一个私有方法,通过重新定位新添加的组件(向下)来执行排序的堆属性。
- HeapifyDown 技术:一个私有方法,特别地将根元素放到其正确的位置(降序位置)。
- Push 技术:公开策略之一是通过调用 heapifyUp 来在堆中添加一个新节点,该节点将满足堆属性。
- Pop 技术:创建一个公共函数 remove_root_element,并具有 heapifyDown 功能,以在作为其参数时恢复堆属性。
- PrintHeap 方法:一个公共方法,用于打印堆中的项目。
- Size 策略:公共技术,用于获取堆大小。
- Top 技术:一个公共方法,用于获取最大堆中顶层元素的值(最大堆中的最小值)。
- Swap 方法:一个私有实用函数,用于交换 heapArray 中位于相应位置的两个元素。
- Main 方法(模型使用):通过一系列任务执行 CustomHeaps 类的使用。
堆(内存堆)“堆”是计算机内存的一部分,用于进行动态内存分配。在 C 和 C++ 等某些编程语言中,可以通过调用 malloc 和 new 函数在堆上分配内存。在堆上分配的内存可以保留,直到被物理释放,因此提供了一种比堆栈更灵活的方法。 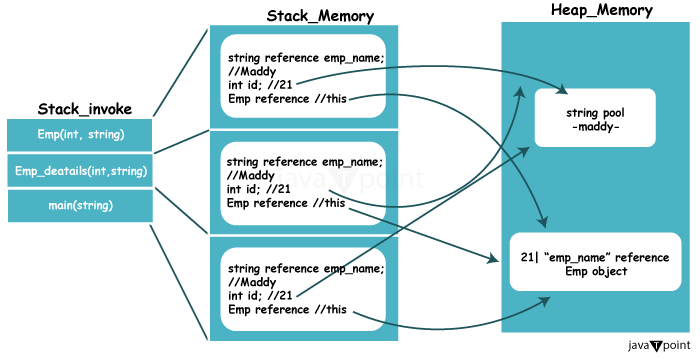 Java 代码实现说明 1. 数组初始化 代码创建一个大小为 5 的整数数组 arr。 int arr[] = new int[5]; 2. 数组填充 使用 for 循环在数组中创建从 0 到 4 的值。 for (int i = 0; i< 5; i++) { arr[i] = i; } 现在,数组已变为 {0, 1, 2, 3, 4}。 3. 数组访问和输出 然后,代码片段显示第一个数组元素 (arr[0]) 和第二个元素 (arr[1])。 System.out.println(arr[0]); 将输出第 0 个元素。 System.out.println(arr[1]); - 将显示第二个元素 (1)。 4. 输出:代码详细描述了如何初始化、填充和检索简单整数数组的元素。 “一个”堆与“那个”堆的关系?- 堆只是一个描述任何堆数据结构的通用术语,它是计算机科学中的一个编程概念。通常,当使用“堆”一词时,指的是在相关场景中发现的特定堆。
- “一个”堆是面向堆数据结构的一个抽象数据结构,从而展示了它的属性和行为。“那个”堆是被称为堆的最广泛的数据结构的一个实际实例,该实例存在于特定的软件或特定的应用程序中。
- “一个”堆通常在许多算法问题、数据结构设计和理论分析中代表堆数据结构。“那个”堆是感兴趣的对象,您将处理在当前程序或算法中正在操作或分析的特定堆实例。
结论简而言之,堆有两种用法:第一,它可以是用于优先队列操作的数据结构,如二叉堆或二项堆;第二,它可以是计算机内存中用于动态内存分配的区域。在数据结构方面,堆主要构建在具有某些特殊属性的二叉树概念之上。
| 