Java Boyer Moore2025 年 5 月 12 日 | 阅读 9 分钟 Boyer-Moore 算法 是由 **Robert S. Boyer** 和 **J Strother Moore** 于 1977 年开发的字符串搜索或匹配算法。它是一种广泛使用且最高效的字符串匹配算法。它比暴力算法快得多。在本节中,我们将讨论 **Boyer-Moore 算法、特性** 及其 **在 Java 程序中的实现**。它的运行时间复杂度为 **O(nm+s)**。最坏情况是 T=ssssssss……………ssssssss P=psssssssss 上述序列可能出现在图像和 DNA 序列中。 Boyer Moore 算法的特性
该算法基于以下两种启发式方法
让我们了解 Boyer-Moore 算法的工作原理。 Boyer-Moore 算法的工作原理该算法从给定模式的最右边字符开始跟踪字符,然后向左移动。在发生任何不匹配和完全匹配模式的情况下,它使用两个预先计算的函数,分别向右和向左移动字符。这两个预先计算的移位函数称为**好后缀移位**(或**匹配移位**)和**坏字符移位**(或出现移位)。 注意:为了匹配模式,请按从左到右的顺序对齐字符,并按从右到左的顺序比较字符。坏字符移位发生不匹配时,跳过对齐,直到满足以下条件之一
例如,考虑下面给出的文本 (T) 和模式 (P)。  让我们开始匹配模式。 步骤 1:按从左到右的顺序对齐字符,并按从右到左的顺序比较字符。 我们看到 P 的最后三个字符与 T 中的字符匹配。第四个字符 (T) 不匹配。根据上面讨论的规则,跳过对齐,直到不匹配变成匹配。由于 P 中的第七个字符 (C) 与 T 中的 C 匹配。  步骤 2:向右跳过三个字符以匹配模式。 移动后,再次从右到左比较字符。第一个字符匹配。我们观察到字符 A 不出现在 P 的左侧。在这种情况下,P 移动到 T 中不匹配的字符 (A) 之后。  步骤 3:将 P 移过不匹配字符,我们得到  模式已匹配。 注意:坏字符移位可能为负值。由于 Boyer-Moore 算法在移位字符时会应用好后缀移位和坏字符移位之间的最大值(跳过的字符数)。好后缀移位设 t 是内循环匹配的子串,然后跳过字符直到
例如,考虑以下模式。  步骤 1:从右到左比较字符。我们看到 P 的最后三个字符与 T 中用 **t** 标记的字符匹配。  步骤 2:跳过字符,直到 P 和 t 之间没有匹配。我们观察到 P 的前四个字符(从左到右)(C T T A C)与 t 的最后五个字符匹配。  步骤 3:跳过三次对齐以获得匹配。因此,我们得到匹配。  上述两个移位函数可以定义如下 好后缀移位函数存储在一个名为 **bmGs** 的表中,大小为 **m+1**。表 **bmGs** 的计算使用一个名为 **suff** 的表,定义如下 坏字符移位函数存储在一个大小为 σ 的表 **bmBc** 中。对于 ∑ 中的 c Boyer Moore 模式匹配示例考虑以下模式。  让我们开始匹配。 步骤 1:从右到左比较字符。我们看到第一个字符不匹配,即 G 与 T 不匹配。  步骤 2:现在,跳过字符,直到找到匹配。六个字符后找到匹配。此处,好后缀移位规则不适用。  bc: 6, gs: 0 根据坏字符移位,P 越过不匹配字符(即 G)。  步骤 3:再次,从右到左比较字符。我们看到 P 的前三个字符(t)与 T 匹配,第四个不匹配。  在这里,我们可以应用两个函数,即坏字符后缀和好字符后缀。如果应用坏字符后缀,它只跳过一个字符。如果应用好字符后缀,它会跳过两次对齐。因此,我们将应用好字符后缀,因为算法规定,要跳过更多对齐。因此,我们跳过两次对齐。 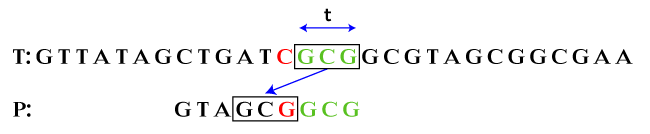 bc: 0, gs: 2 通过三次对齐移位后,我们得到  bc: 2, gs: 7 在这里,我们观察到 C 不出现在 P 的左侧。因此,坏字符对齐跳过 **两次** 对齐,好字符对齐跳过 **七次** 对齐。 步骤 4:移位字符后,我们看到字符串已匹配。  在上述模式中,我们跳过了 15 次对齐,T 的 11 个字符被忽略了。 Boyer Moore 预处理阶段模式 **T: A A T C A A T A G C** 和 **P: T C G C** 的预先计算的跳过可以定义如下。在上面的模式中,我们使用了坏字符移位函数。  上表定义了跳过的对齐(字符)数量。 Boyer Moore 算法伪代码模式搜索 Java 程序让我们看看模式搜索 Java 程序。在下面的程序中,我们实现了暴力字符串搜索算法。 PatternSearchingExample.java 输出 Brute force looking for abddef in abcfefabddef Found match in the given text at index 6 Boyer-Moore looking for abddef in abcfefabddef Found match in the given text at index 6 让我们用 Java 程序实现该算法。 Boyer Moore Java 程序让我们实现 Boyer-Moore 算法并通过 Java 程序搜索模式。 BoyerMooreImplementation.java 输出 Patterns occur at character = 0 Patterns occur at character = 5 Patterns occur at character = 10 让我们看另一个 Java 程序,在该程序中我们实现了不同的模式搜索逻辑。下面的程序检查是否在文本中找到了指定的模式。 BoyerMooreExample.java 输出 Pattern Not Matched text: aabbccdef word: cde exp: 0, res: 5 Pattern Not Matched text: zzzzaaapppxyzabc word: pqrs exp: 1, res: -1 Pattern Matched Pattern Matched Pattern Matched Pattern Not Matched text: pqrsabcdxyzamnop word: cdxyza exp: 1, res: 6 Pattern Matched Pattern Matched |
javax.naming.CompositeName 是一个类,包含一个 get() 方法。要获取此复合名称对象的组件,请使用 CompositeName 类。通过提供的位置,从复合名称对象中获取该位置上存在的组件...
阅读 2 分钟
问题陈述给定一个二进制字符串,我们需要找到给定二进制字符串中 0 和 1 的最大差值。在这里,我们将 0 视为 +1,将 1 视为 -1,然后寻找连续子数组的最大值。这个子数组的最大和……
阅读 4 分钟
单例设计模式是 Java 和其他面向对象编程语言中最常用的模式之一。它确保一个类只有一个实例,并提供对该实例的全局访问点。虽然单例在许多场景下都很有价值,但是...
5 分钟阅读
Java 静态类型与动态类型 Java 是一种强类型语言,它将变量、表达式和对象分类为静态类型。然而,Java 也通过使用其面向对象的特性来支持动态类型。在本节中,我们将探讨 Java 中的静态类型和动态类型概念...
5 分钟阅读
Java中最长的奇偶子序列是一个问题,其中必须在大小为s的非负数组中找到一个子序列,使得该子序列以交替的方式包含交替的奇数和偶数。因此,必须计算...
7 分钟阅读
OOPS MCQ 1) 以下哪种语言是作为第一种纯粹面向对象的语言开发的? SmallTalk C++ Kotlin Java 显示答案 工作区 答案:a. SmallTalk 说明:这种编程语言是作为第一种纯粹的 OOPS(面向对象)语言发明的。该语言由 Alan Kay 在 20 世纪 70 年代初设计。 2) 谁开发了面向对象编程? Adele...
阅读 13 分钟
JFileChooser 是 java Swing 包中的一个类。java Swing 包对于 JavaTM Foundation Classes (JFC) 至关重要。JFileChooser 包含许多有助于在 Java 中构建图形用户界面的元素。Java Swing 提供按钮、面板、对话框等组件。JFileChooser...
5 分钟阅读
在 Java 中,String 是一个使用广泛的类,它表示字符序列。Java 中的 String 是不可变的,这意味着一旦创建了 String 对象,它的值就不能被改变。要了解更多 Java String 任何修改都会导致创建新的 String 对象……
阅读 8 分钟
对象是 OOPs 语言的基本构建块。在 Java 中,没有对象我们就无法执行任何程序。有多种创建 Java 对象的方法,我们将在本节中讨论,并学习如何创建……
阅读 6 分钟
在本节中,我们将学习自守数及其示例,并创建 Java 程序来检查数字是否为自守数。什么是自守数?如果一个数字的平方以该数字本身结尾,则称该数字为自守数。
阅读 3 分钟
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
