用于模式搜索的有限自动机算法2025 年 5 月 12 日 | 阅读 6 分钟 使用 有限自动机 进行模式搜索是一种 字符串匹配技术,它使用有限状态机在文本中定位模式的出现。它会预处理模式以创建转换表,从而能够使用恒定的状态转换时间来高效扫描文本。 这种方法保证了确定性和快速搜索,使其成为文本处理和计算语言学等应用的理想选择。 什么是有限自动机?有限自动机是识别输入序列中模式的抽象机器,为理解计算机科学中的正则语言奠定了基础。自动机由几个状态和规则组成,允许它根据输入符号从一个状态转换到另一个状态。 如果机器在处理完输入后处于接受状态,则接受;否则,则拒绝。 有限自动机的关键特征
有限自动机的形式化定义有限自动机是一种可以定义为元组的机器 {Q, Σ, q, F, δ} 其中 Q: 一个有限的状态集合。 Σ: 一组输入符号。 q: 初始状态。 F: 最终状态的集合。 δ: 转换函数。 什么是模式搜索?模式搜索,也称为模式匹配,是 计算机科学 中的一个基本主题,具有文本处理和生物信息学等多种应用。基于有限自动机的模式查找算法是解决此问题的有效方法。 用于模式搜索的有限自动机算法输入 字符串 为 text[0….. k - 1],模式字符串为 ptr[0…. l - 1]。我们需要开发一个函数来查找给定字符串中的模式。此 函数 将接受两个参数:char ptr[] 和 char text[]。然后该函数将返回模式字符串 ptr[] 在输入字符串 text[] 中出现的次数。我们可以假设输入字符串比模式字符串长 (k > l)。 示例示例 1 示例 1 输入: text = “TEST SAMPLES SENT FOR TEST.” ptr = “TEST” 输出: 在 0 处识别到模式 在 22 处识别到模式 解释  示例 2 输入: text = “PQRSPPSPTRRPPSPPSPTRQS” ptr = “PPSP” 输出: 在 4 处识别到模式 在 11 处识别到模式 在 14 处识别到模式 解释  示例 3 输入: text = “STOPTOTTSPTO” ptr = “PTO” 输出: 在 3 处识别到模式 在 9 处识别到模式 解释  有限自动机用于模式搜索算法的通用算法步骤 1: 创建转换函数 (TF) 表 步骤 1.1: 转换函数 (TF) 表将根据输入符号和字母显示 DFA 状态之间的转换。 步骤 1.2: 我们可以通过遍历所有可能的州和符号来生成它,并根据当前状态和输入符号选择下一个状态。 步骤 1.3: get Next State 方法使用当前状态和输入符号来确定下一个状态。 步骤 2: DFA 遍历文本 步骤 2.1: 创建 TF 表后,我们应该在文本上遍历 DFA 以查找和匹配输入文本中模式的出现。 步骤 2.2: 我们将从初始状态(状态 0)开始,DFA 将根据文本中的字符转换到后续阶段。 步骤 2.3: 当 DFA 到达最终状态(代表模式结束)时,如果找到匹配项,则保存该出现的位置索引。 步骤 3: 打印结果 步骤 3.1: 如果在遍历过程中找到匹配项,我们应该打印出现的位置索引。 步骤 3.2: 如果未找到匹配项,我们将输出“在输入文本中未找到模式。” 有限自动机用于模式搜索算法的实现模式匹配自动机非常高效,因为它们仅评估每个文本一次,每个文本字符花费相同的时间。因此,我们可以说字符串匹配所需的时间是 O(K),其中 K 是文本字符串的长度。但是,预处理时间(构建有限自动机所需的时间)可能很长。 现在让我们来看一下模式 STSTSVS 的有限自动机。 上面的图表提供了模式 STSTSVS 的图形和表格表示。 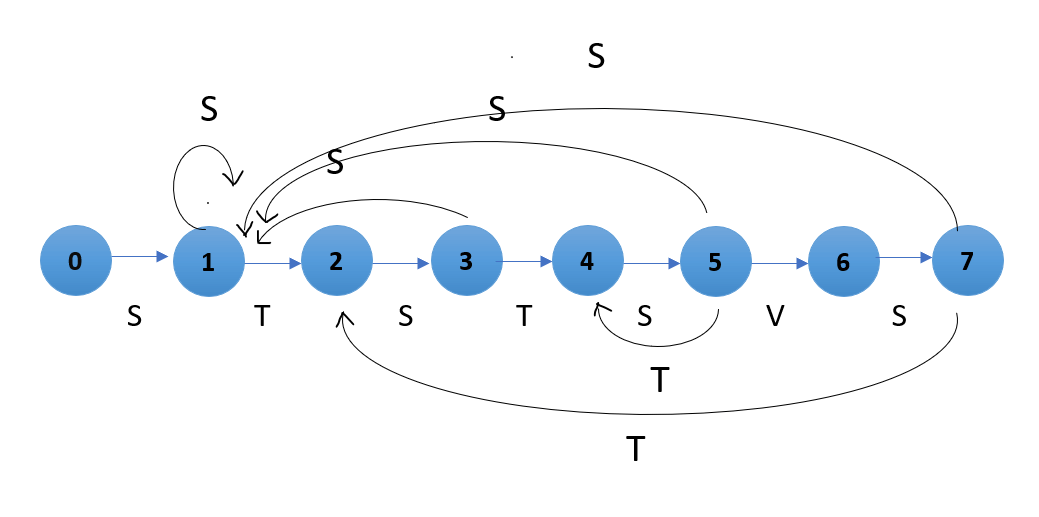 表格表示  E 表示转换函数(FA 结束) 有限自动机中的状态数将是 k+1,其中 k 是模式的长度。构建有限自动机的基本目标是确定每个可能字符从当前状态到未来状态的转换。 给定一个字符 b 和一个状态 c,我们可以通过评估字符串“ptr[0..c-1]b”来推导出下一个状态,该字符串是模式字符 ptr[0]、ptr[1] 和 ptr[c-1] 与字符 b 的简单组合。目标是确定提供的模式中最长的、作为“ptr[0..c-1]b”后缀的前缀的长度。长度值决定了下一个状态。 例如,考虑如何在上面的图中从当前状态 5 和字符 'T' 确定下一个状态。我们必须考虑字符串“ptr[0..4]S”,即“STSTST”。模式中最长的、作为“STSTST”后缀的前缀的长度是 4(“STST”)。因此,下一个状态(状态 5 之后)是字符 'T' 的 4。 上图中当前状态 5 和字符 'T'。首先,我们必须考虑字符串“ptr[0..4]T”,即“STSTST”。模式中最长的、作为“STSTST”后缀的前缀的长度是 4(“STST”)。因此,下一个状态(状态 5 之后) 在接下来的程序中,我们将创建一个函数来生成有限自动机。该函数的时间复杂度为 O(k3 * l),其中 k 是模式字符串的长度,l 是字母表大小(给定模式和文本中所有可能的字母总数)。 该实现旨在获得所有以最长可能序列开头的缀,该序列可以是“ptr[0 … c - 1]b”的后缀。可以使用几种实现来以 O(k*l) 的时间构建有限自动机。 输出 The Pattern identified at the index 0 The Pattern identified at the index 8 The Pattern identified at the index 14 The Pattern identified at the index 6 The Pattern identified at the index 24 下一个主题Java 与 Go |
本文旨在解释如何在 Java 中创建抽象类的实例。我们将研究创建抽象类实例的不同方法以及每种方法的优缺点。我们还将讨论重要性...
阅读 6 分钟
队列是另一种线性数据结构,它像其他数据结构一样用于存储元素,但方式有所不同。简单来说,我们可以说队列是 Java 编程语言中的一种数据结构...
阅读 10 分钟
霍夫曼编码算法由 David A. Huffman 于 1950 年提出。它是一种无损数据压缩机制。它也被称为数据压缩编码。它广泛用于图像(JPEG 或 JPG)压缩。在本节中,我们将讨论霍夫曼编码...
阅读 12 分钟
在 Java 中,有几种方法可以将 Set 转换为 List,每种方法都有其优点:使用 ArrayList 构造函数通常是最简洁和最常见的方法。我们可以直接将 Set 实例传递给 ArrayList 的构造函数。有...
5 分钟阅读
Java 是世界上最受欢迎的编程语言之一,其主要特性之一是定义和使用函数的能力。Java 中的函数是执行特定任务的代码块,用于组织代码和……
阅读 4 分钟
Java.lang.String 或 String 类,是 API 中的一个重要类。String 类在 Java API 中具有许多许多程序员并未立即意识到的独特功能。理解 String 类是学习 Java 的先决条件。它...
阅读 4 分钟
确定给定三个整数 a、b 和 c 的最长快乐字符串。如果存在多个最长快乐字符串,则返回其中任何一个。如果不存在这样的字符串,则返回空字符串“”。快乐字符串是指...
阅读9分钟
在 Java 中,StringIndexOutOfBoundsException 是一个运行时异常,当您尝试访问字符串中无效索引处的字符时会发生。尝试访问负索引或超出字符串长度范围的索引处的字符会导致此异常...
阅读 3 分钟
Java 中的骑士游历问题 骑士游历问题是一个著名的回溯算法案例。它涉及骑士在棋盘上移动,以便恰好访问每个方格一次。给定一个 (n x n) 的棋盘和一个起始位置,目标是……
阅读 6 分钟
Java 中的递归是一个函数/方法不断调用自身的进程。在编程语言中,如果程序允许我们在相同的方法名称内调用一个方法,则称为递归调用。它使代码最小化,但具有挑战性...
阅读 4 分钟
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
