Java 中的链表实现2025年8月17日 | 阅读 10 分钟 这是一种存储项目列表的方式,但这些项目在内存中并不相邻存储。相反,每个项目都链接到下一个项目,形成一个链。这种设置使得在列表的任何位置添加或删除项目变得非常容易,而无需移动其他所有内容,这对于数组等其他类型的列表来说可能是一个缓慢的过程。此列表中的每个项目都称为节点。 链表元素节点 (Node): 链表构建块的概念。每个节点通常包含两部分 数据 (Data): 存储在节点中的实际值或信息。 指针 (Pointer): 指向序列中下一个节点的引用。 头 (Head) 或 前端 (Front): 指向链表第一个节点的引用。当列表为空时,头为 null。 尾 (Tail) 或 末端 (Rear): 指向链表最后一个节点的引用。 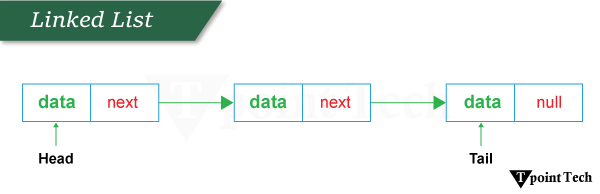 它是如何工作的?链表的工作原理是将每个项目存储在其单独的容器中,称为节点。与数组不同,这些节点不并排放在内存中。相反,每个节点都包含数据和它的地址。 示例在供应链系统中,添加或删除项目非常有效。如果我们向中间插入一个新项目,只需要更新几个指针。插入点之前的节点指向新节点,新节点指向插入点之后原来的节点。无需移动所有后续项目,这在数组等其他数据结构中通常是必需的。 链表实现链表可以通过以下两种方式实现
使用类手动实现这种方法可以帮助你理解单向链表的内部结构。 示例编译并运行输出 LinkedList: 1 2 3 4 使用内置类Java 提供了内置的 LinkedList 类来实现链表。LinkedList 类属于 java.util 包。 阅读更多 Java 链表 示例编译并运行输出 LinkedList: [Cat, Dog, Horse] First Element: Cat Last Element: Horse 链表的常见操作以下是对链表执行的关键操作 插入
删除
遍历 (Traversal): 从头到尾访问列表中的每个节点以执行操作。 搜索 (Search): 查找具有特定数据值的节点。这通常涉及遍历列表直到找到该值或到达列表末尾。 获取 (Get/Access): 检索特定索引处节点的數據。 示例:链表插入操作示例编译并运行输出 Linked List after insertions: 5 -> 10 -> 12 -> 15 -> null 示例:链表删除操作示例编译并运行输出 Original List: 10 -> 20 -> 30 -> 40 -> 50 -> null Value not found List after deletions: 20 -> 40 -> null 示例:遍历链表示例编译并运行输出 Linked List: 5 -> 15 -> 25 -> 35 -> null Total nodes: 4 Sum of node values: 80 示例:搜索链表示例编译并运行输出 Linked List: 10 -> 20 -> 30 -> 40 -> null Searching for 30 (Iterative): true Searching for 30 (Recursive): true Searching for 99 (Iterative): false Searching for 99 (Recursive): false 示例:检索特定索引处节点的数据示例编译并运行输出 Linked List: 100 -> 200 -> 300 -> 400 -> null Data at index 2 (Iterative): 300 Data at index 2 (Recursive): 300 Data at index 5: null 优点
缺点
应用
结论链表是计算机科学中一种基本且通用的数据结构。与数组不同,它们的非连续内存分配允许高效的插入和删除,使其成为需要动态大小和频繁修改的场景的理想选择。 即使存在指针带来的轻微内存开销和无随机访问的缺点,它们在处理顺序数据方面的灵活性以及在构建堆栈和队列等抽象数据类型方面的关键作用,使其在从系统编程到复杂算法的各种应用中都不可或缺。 理解链表是掌握更高级数据结构和优化动态数据处理代码的基石。 下一主题Java 中的哈希技术 |
在 LTS 版本 11 之后的版本。JDK 12 是 6 个月发布周期的一部分。于 2019 年 3 月 19 日发布,它是一个非 LTS 版本,不提供长期支持。SE 平台的开源参考实现是...
5 分钟阅读
Java 提供的按位运算符之一是 XOR。XOR(也称为异或)接收两个布尔操作数,如果它们不同则返回 true。当提供的两个布尔条件不能同时为真时,XOR 运算符就是...
7 分钟阅读
异常的一般含义是故意遗漏,而错误的含义是准确或不正确的操作。在 Java 中,Exception 和 Error 都是 Java Throwable 类的子类,它属于 java.lang 包。但是存在……
阅读 3 分钟
? 在 Java 中,字符串分割是一项重要且常用的操作。Java 提供了多种分割字符串的方法。但最常见的方法是使用 String 类的 split() 方法。在本节中,我们将学习如何分割一个...
阅读9分钟
Java 中的多线程提供了许多好处,但也存在一些潜在的缺点:增加复杂性:多线程程序可能更复杂且难以理解、设计和维护。尤其是在处理共享资源、同步和死锁时。更高的内存消耗:每个线程都需要自己的...
阅读 6 分钟
在本节中,我们将创建 Java 程序来查找给定范围内所有素数的总和。在继续本节之前,让我们看一下关于素数的重要事实。素数是一个大于 1 且...
阅读 4 分钟
Java 是一种多功能、面向对象的编程语言,它采用了一种称为方法绑定的概念。方法绑定是指将方法名称与实际方法实现连接的过程。Java 中有两种方法绑定:静态绑定和动态绑定。什么是方法...
阅读 4 分钟
Java 库中已有的异常被称为内置异常。这些异常可以定义错误情况,以便我们理解出现此错误的原因。内置异常的类型内置异常有两种:检查异常和非检查异常。检查异常 检查...
阅读 8 分钟
树的**遍历**通常用于树数据结构,以便以某种特定顺序访问所有节点。另一种相当引人入胜的遍历模式是**逆序层序遍历(螺旋形)**,其中在每一层从……
阅读 6 分钟
两层和三层数据库设计的结构和功能根本不同。在学习两层和三层架构之间的区别之前,让我们先了解两层架构。客户端和数据库服务器。在这种情况下,客户端直接连接到数据库,...
阅读 4 分钟
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
